Introduction
Marketing, technology, and business leaders keep asking the same question in 2025: how do we optimize for large language models (LLMs) like ChatGPT, Gemini, and Claude? The answer is taking shape as a new practice many now call Generative Engine Optimization, or GEO. GEO borrows the best from SEO while adapting to how AI systems find, interpret, and present information. This is where strong Content Marketing comes in; it is about tracking your brand’s presence in AI answers and improving the odds that those answers mention and cite you.
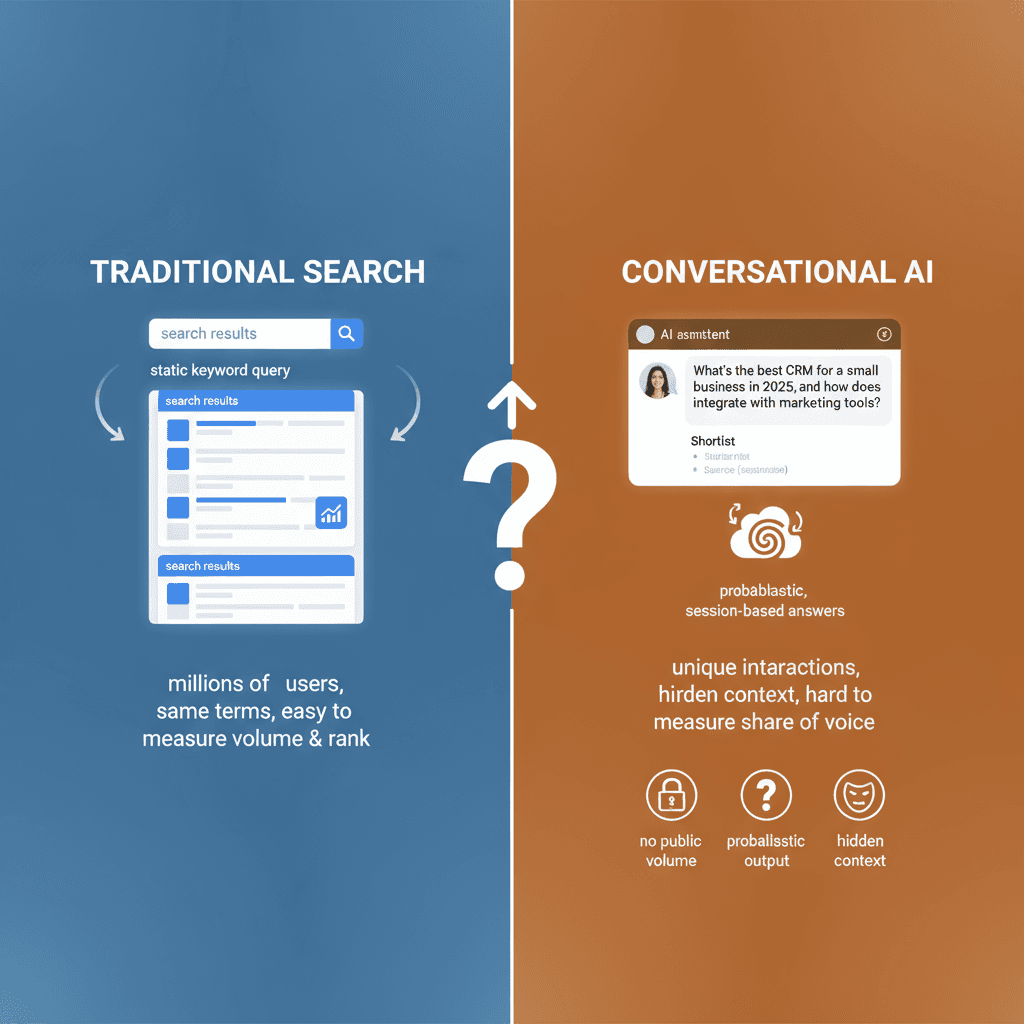
What makes this shift urgent is the steady rise of AI-assisted research. Buyers begin with a conversational prompt, not a static keyword. They get instant summaries, recommendations, and shortlists. Your brand may be present as a citation, a mention, or neither. The difference can affect awareness, trust, and demand. Yet most teams still work in the dark because measurement is new, and tools are early.
This article gives decision makers a clear, practical roadmap. First, how to track and monitor your brand’s share of voice across LLMs. Second, how to improve your visibility and performance within them. We will focus on what you can measure today, how to interpret results, which tactics move the needle, and how to set expectations with your executive team. Throughout, we will keep the language simple, the guidance actionable, and the focus on outcomes.
Why LLM queries are different
Traditional search is built on repeatable phrases. Millions of users type the same terms, which makes volume and rankings easier to measure. LLMs are different. People interact in a conversational way. They ask, refine, and chain questions. Session context influences answers. Two users can ask “best CRM for SMB” and get different responses depending on prior prompts, hidden embeddings, and model settings.
Three factors drive the difference:
- No public volume: LLMs do not publish query frequencies or search volume equivalents.
- Probabilistic output: The same prompt can produce different answers due to sampling and decoding choices.
- Hidden context: History, session state, and retrieved documents shape answers in ways you cannot always see.
These structural differences change visibility and measurement. In SEO, visibility is a blend of rank position and click-through rate. In LLMs, it is a blend of whether you are cited, how you are described, whether you appear in a shortlist, and if your brand is even named. Because exact-match keywords are less important in a conversation, topic coverage, entity clarity, and authority signals matter more. That is why GEO focuses on entities, mentions, and source authority, not just keywords and links.
Tracking: The foundation of LLM optimization
Just as SEO Thailand matured when tracking improved, GEO will only scale when visibility is measurable. Today we are early—think pre-suite days before the big SEO platforms standardized the market. Still, leaders can put a solid tracking baseline in place now and start learning, often beginning with a comprehensive SEO Audit to understand their current standing.
The goal is simple: measure how often your brand shows up in LLM answers for a representative set of queries, how you are presented, and who else is present. Over time you want to see your share of voice rise, your mentions become more accurate, and your citations point to stronger assets. This turns random-seeming variability into a pattern you can manage.
The polling-based model for measuring visibility
Because LLM answers vary, you need to sample repeatedly. The best current method borrows from election polling:
- Build a representative query set: Choose 250–500 high-intent prompts that match how people research your category. Include generic prompts (“best X for Y”), mid-funnel questions (“X vs Y for Z use case”), and brand prompts (“Is Brand A good for [job]?”).
- Sample often: Run the same queries daily or weekly across engines (ChatGPT, Gemini, Claude, and if useful, Perplexity or others). Keep the prompt phrasing stable during each sampling run.
- Record mentions and citations: Track when your brand appears as text references (mentions) and when your pages are cited as sources (citations). Log the specific URLs and the way your brand is described.
- Compare share of voice: Calculate your share of mentions and citations against a fixed competitor set. Do this by query and by theme.
- Aggregate over time: Use rolling averages to smooth out noise. Over weeks and months, a stable visibility signal will emerge.
Early tools can automate parts of this process. Platforms such as Profound, Conductor, and OpenForge are adding LLM tracking features that run prompts, parse answers, and store results. They are not perfect, but they bring structure, scale, and repeatability. Even if you start with scripts and spreadsheets, the polling model is the right mental model.
Building a multi-faceted tracking framework
Share of voice in answers is critical. But it is not the whole story. You also want to see if AI-driven visibility translates into action. Because no single tool can show the full path today, layer several signals:
- Share of voice (SOV) tracking: Use your polling runs to produce an SOV baseline by engine, theme, and query type. Separate mentions and citations. Mentions indicate awareness. Citations signal trust.
- Referral tracking in GA4: Create a custom dimension to capture known LLM referral patterns where possible. While some LLMs do not pass referrers, you can still spot spikes linked to your sampling cadence or to new content entering answers.
- Branded homepage traffic in Search Console: Many users validate AI outputs by searching your brand name right after seeing an answer. Track branded homepage impressions and clicks. If that rises at the same time your SOV climbs, you likely influenced behavior through LLMs.
Treat these data as directional. There is no perfect attribution yet. Be wary of anyone promising complete visibility. Instead, use trends across these signals to inform decisions, set priorities, and explain progress to stakeholders.
Estimating LLM ‘search volume’
Leaders ask a fair question: which topics inside LLMs are big enough to matter? Because there is no LLM search volume, shift from query-level thinking to theme-level thinking. Estimate relative demand this way:
- Start with SEO volume: Use your top organic keywords with clear commercial intent as a proxy. For example, if a key area for your Digital Marketing for Startups strategy like “best payroll software for startups” drives strong SEO traffic, assume a portion of those researchers also ask LLMs similar questions.
- Layer in AI adoption: Estimate the share of your audience using LLMs for research. In high AI-adoption industries, 20–25% of users may rely on LLMs at some stage. In slower-moving fields, 5–10% is a safer baseline. Apply those percentages to SEO volumes to get directional LLM demand.
- Use inferential tools: Some emerging platforms monitor API patterns and model outputs to estimate query clusters and their growth. The numbers are not exact, but they help rank topics. Expect rapid improvement in these models over the next one to two years.
This. Please add relevant links to the post as per the instructions provided and return the full blog post with the links inserted, keeping everything else unchanged.






