
Every second, billions of ad interactions happen across Facebook, Instagram, and WhatsApp. Someone scrolls past a shoe ad. Another clicks a home improvement offer. A third swipes through a sponsored story on the Instagram Ads Service. Behind every one of those moments, a machine learning system is deciding which Display Advertising to show, to whom, and when.
For years, the engineers responsible for improving those systems worked through a process that was slow and almost entirely manual. Craft a hypothesis, set up a training run, wait days for results, debug what went wrong, adjust, repeat. And as Meta’s models got more sophisticated, meaningful improvements became harder and harder to find.
That’s the problem the Ranking Engineer Agent, known as REA, was built to solve. REA isn’t another AI tool that helps engineers write code faster or answers questions in a chat window. It’s an autonomous agent that takes over the full machine learning experimentation lifecycle, from forming hypotheses to running experiments to analyzing results, without needing someone to babysit it along the way.
The results from its first production rollout are genuinely hard to dismiss.

- Why Optimizing Ads Ranking Models Takes So Long
- The Sequential Nature of Manual ML Experimentation
- Introducing REA: Meta’s Autonomous AI Agent for ML Experimentation
- How REA Manages Multi-Week ML Workflows Without Constant Human Input
- REA’s Three-Phase Planning Framework and Resilient Execution Model
- Real-World Results: What REA Delivered in Its First Production Rollout
The Bottleneck That Was Slowing Meta Ads Ranking Improvements
Why Optimizing Ads Ranking Models Takes So Long
Facebook Ads ranking is not a simple system. The models deciding which ads get shown are trained on massive datasets, involve intricate feature engineering, and require careful tuning. Getting a meaningful accuracy gain is genuinely difficult — and it requires a lot of experimentation.
Each experiment cycle isn’t a matter of hours. A single full cycle covering hypothesis crafting, training configuration, actual training runs, evaluation, debugging, and iteration typically spans days to weeks. If something breaks mid-run — and in large-scale ML infrastructure, things break regularly — an engineer has to diagnose what happened before starting again.
Multiply that across a team handling multiple models at once, and the pace of progress becomes a real constraint. Engineers end up spending enormous amounts of time managing the mechanics of experimentation rather than thinking creatively about what to try next.
The problem isn’t that these engineers lack skill or ambition. The process itself is structured in a way that limits how many ideas can actually be tested in a given month. When you can only run a handful of experiments per model, you’re inevitably leaving potential improvements on the table.
The Sequential Nature of Manual ML Experimentation
The deeper issue is that traditional ML experimentation is almost entirely sequential. Form a hypothesis, test it, review the result, move to the next step. Each action depends on finishing the previous one. There’s very little parallelism, and stepping away from the process for any stretch of time means losing momentum or missing something important.
At Meta’s scale, this compounds fast. The team handling Meta Ads Ranking models is working with systems that have already been heavily optimized over years. The easy wins are gone. Every improvement requires more sophisticated reasoning, more careful experimental design, more rigorous analysis.
When your models are already mature, the manual approach stops being a minor inconvenience and starts becoming a genuine ceiling on what the team can achieve. That’s the wall Meta was running into, and it’s the core reason why a different approach became necessary.
Introducing REA: Meta’s Autonomous AI Agent for ML Experimentation
How REA Differs From Reactive AI Assistants
Most AI tools in engineering workflows today are reactive. You ask them something, they respond. You give them a task, they complete it. The human is always the one driving the process forward, and the interaction is bounded by the session.
REA works differently. It’s an AI agent that takes ownership of end-to-end ML workflows across multi-day timelines. Once an engineer approves a plan and a compute budget upfront, REA drives the process from there — deciding which experiments to run next based on results it’s already collected, adapting when things go wrong, and continuing without needing constant check-ins.
This distinction matters more than it might seem at first. A reactive assistant makes individual tasks faster. An autonomous agent like REA changes the fundamental structure of how the work gets done. Engineers go from operating an experiment pipeline to reviewing experiment outcomes. Their attention shifts from managing mechanics to evaluating results and making higher-level calls.
REA is closer to what researchers call a “long-horizon” AI system. It doesn’t just respond to prompts. It maintains state, tracks progress toward a goal, and makes sequential decisions over an extended period to keep moving toward that goal.
Three Core Challenges REA Was Built to Solve
The team at Meta identified three distinct problems that any autonomous ML experimentation agent would need to handle:
The first is long-horizon autonomy. ML experiments don’t complete in minutes — training runs can take many hours or days. An agent that needs a human present and active throughout cannot scale. REA had to operate reliably across multi-day timelines without continuous supervision.
The second is high-quality hypothesis generation. Running experiments autonomously is only useful if the experiments themselves are worth running. Generating hypotheses that are genuinely likely to improve model performance — rather than random configurations that waste compute — required a sophisticated approach to knowledge retrieval and research synthesis.
The third is resilient operation under real-world infrastructure. Large-scale ML infrastructure is messy. Jobs fail. Resources become unavailable. Training runs go unstable. An agent that escalates every problem to a human engineer defeats the whole purpose of automation. REA needed to handle common failure modes on its own.
These three challenges shaped every design decision in how REA was built.
How REA Manages Multi-Week ML Workflows Without Constant Human Input
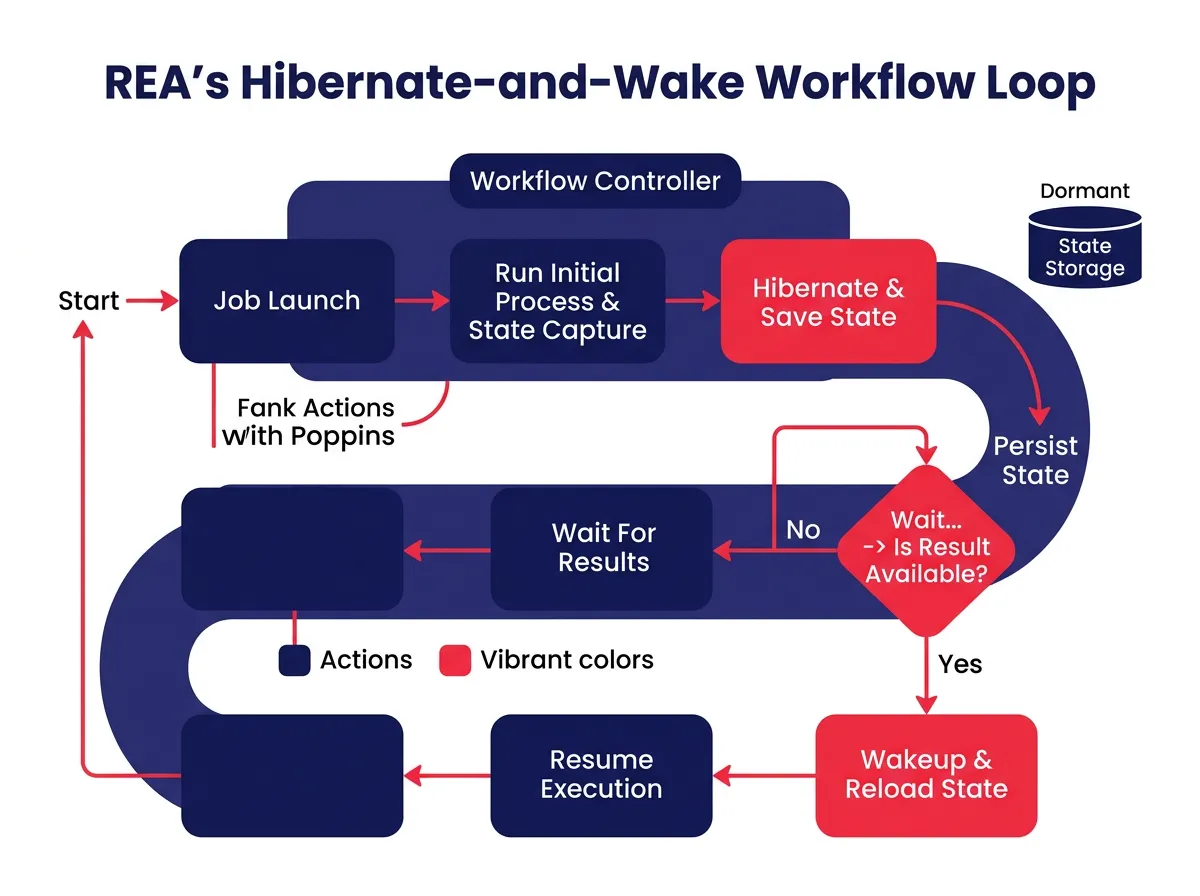
The Hibernate-and-Wake Mechanism Explained
One of the most practical engineering problems REA had to solve is also one of the most obvious: what does an AI agent actually do while it’s waiting for a training job to finish?
In a traditional workflow, an engineer submits a training job and moves on to other work while it runs. They check back periodically to see if results are ready. That works fine for humans but is poorly suited to an autonomous agent that needs to resume a specific workflow state when the job completes.
REA solves this with a hibernate-and-wake mechanism. When REA launches a training job or evaluation run, it serializes its current state — where it is in the experimentation plan, which hypotheses have been tested, which results have been collected — and goes dormant. Not idle in a resource-intensive way. Effectively paused.
When the job completes, a callback wakes REA back up, restores its full state, and picks up exactly where it left off. This lets REA manage multi-week workflows across many experiments without anyone needing to monitor progress or hand work off between stages.
The hibernate-and-wake design is also what makes REA practical at scale. Because it’s not consuming active compute while waiting, multiple instances can run simultaneously across different models without creating an infrastructure burden.
Generating High-Quality Hypotheses From Two Specialized Sources
Running experiments autonomously is only valuable if the hypotheses being tested are good ones. This is where a lot of simple automation approaches fall apart. Without a strong mechanism for deciding what to try next, an autonomous agent would quickly exhaust obvious ideas and start burning compute on configurations unlikely to go anywhere.
REA addresses this through a dual-source hypothesis engine that draws from two complementary places.
The first is a structured database of historical insights — learnings from past experiments at Meta, including what worked, what didn’t, and under what conditions. When REA is generating hypotheses for a new model, it queries this database to surface configurations and approaches that have historically been productive. This grounds REA in proven patterns rather than requiring it to start from scratch every time.
The second is a deep ML research agent, part of a framework Meta calls Confucius. This agent reads and synthesizes recent ML research to surface ideas that may not yet appear in the historical database — techniques new enough that Meta hasn’t had time to test them yet, but credible enough based on research evidence to be worth trying.
By combining institutional memory from past experiments with fresh ideas from ongoing research, REA’s hypothesis generation ends up richer than either source would produce alone. This dual-source approach is a big part of why REA can keep identifying promising experiments even for models that have already been heavily optimized.
REA’s Three-Phase Planning Framework and Resilient Execution Model
Validation, Combination, and Exploitation: The Three-Phase Approach
REA doesn’t run experiments in whatever order happens to be convenient. It follows a structured three-phase planning framework that gets confirmed with an engineer before any experimentation begins.
Phase 1 is Validation. REA tests individual hypotheses in isolation to establish which ideas hold up when tested on their own. Not every hypothesis that looks promising on paper survives contact with real training data, and Validation is designed to filter out weak ideas before spending more compute on them.
Phase 2 is Combination. Once a set of validated ideas has been identified, REA starts testing combinations. Some ML improvements are additive — combining two techniques that each help independently can produce compounding gains. Others interact in unexpected ways that reduce the benefit of each. Combination is designed to find synergies and flag interactions that wouldn’t be obvious from individual validation results.
Phase 3 is Exploitation. In the final phase, REA focuses compute on the most promising candidates identified through the first two phases. The goal is to get as much improvement as possible out of the best configurations within the approved compute budget.
This structure isn’t just a logical progression — it’s also a safeguard. By front-loading simpler tests and deferring heavier compute investments to later phases, REA avoids wasting resources on ideas that would have been eliminated early if tested individually.





