
ในทุกวินาที มีการตอบสนองต่อโฆษณาหลายพันล้านครั้งเกิดขึ้นทั่วทั้ง Facebook, Instagram และ WhatsApp บางคนเลื่อนผ่านโฆษณารองเท้า อีกคนคลิกข้อเสนอปรับปรุงบ้าน คนที่สามปัดดูสตอรี่ที่ได้รับการสนับสนุนบน Instagram Ads Service เบื้องหลังของทุกช่วงเวลาเหล่านั้น คือระบบ Machine Learning ที่กำลังตัดสินใจว่าจะนำ Display Advertising ตัวไหนมาแสดง ให้ใครเห็น และแสดงเมื่อใด
เป็นเวลาหลายปีที่วิศวกรผู้รับผิดชอบในการปรับปรุงระบบเหล่านี้ ต้องทำงานผ่านกระบวนการที่ล่าช้าและต้องทำด้วยมือแทบทั้งหมด เริ่มจากการตั้งสมมติฐาน, ตั้งค่าการเทรนระบบ, รอผลลัพธ์เป็นวันๆ, ดีบั๊กสิ่งที่ผิดพลาด, ปรับแก้, แล้วทำซ้ำ และเมื่อโมเดลของ Meta มีความซับซ้อนมากขึ้น การค้นหาการปรับปรุงที่มีนัยสำคัญก็ยิ่งยากขึ้นเรื่อยๆ
นั่นคือปัญหาที่ Ranking Engineer Agent หรือที่รู้จักในชื่อ REA ถูกสร้างขึ้นมาเพื่อแก้ไข REA ไม่ใช่เครื่องมือ AI ทั่วไปที่ช่วยวิศวกรเขียนโค้ดได้เร็วขึ้นหรือคอยตอบคำถามในหน้าแชท แต่มันคือ Autonomous Agent (ตัวแทนอัตโนมัติ) ที่เข้ามาดูแลวงจรการทดลอง Machine Learning ทั้งหมด ตั้งแต่การสร้างสมมติฐาน การรันการทดลอง ไปจนถึงการวิเคราะห์ผลลัพธ์ โดยไม่ต้องมีใครมาคอยประกบดูแล
ผลลัพธ์จากการเปิดใช้งานจริงครั้งแรกนั้นยากที่จะมองข้าม

ปัญหาคอขวดที่ชะลอการปรับปรุงการจัดอันดับโฆษณาของ Meta
ทำไมการปรับปรุงโมเดลจัดอันดับโฆษณาถึงใช้เวลานาน
การจัดอันดับ Facebook Ads ไม่ใช่ระบบที่เรียบง่าย โมเดลที่ตัดสินใจว่าโฆษณาใดจะถูกแสดงนั้นถูกเทรนด้วยชุดข้อมูลขนาดมหึมา เกี่ยวข้องกับ Feature Engineering ที่ซับซ้อน และต้องการการปรับแต่งอย่างละเอียด การจะเพิ่มความแม่นยำให้ได้ผลจริงนั้นยากมาก และต้องอาศัยการทดลองจำนวนมาก
รอบการทดลองแต่ละครั้งไม่ได้ใช้เวลาแค่ไม่กี่ชั่วโมง แต่วงจรเต็มรูปแบบที่ครอบคลุมตั้งแต่การสร้างสมมติฐาน, การตั้งค่าคอนฟิก, การรันเทรนนิ่งจริง, การประเมินผล, การดีบั๊ก และการทำซ้ำ มักกินเวลาหลายวันไปจนถึงหลายสัปดาห์ หากมีอะไรพังระหว่างทาง ซึ่งเป็นเรื่องปกติในโครงสร้างพื้นฐาน ML ขนาดใหญ่ วิศวกรจะต้องวินิจฉัยสาเหตุก่อนที่จะเริ่มใหม่อีกครั้ง
เมื่อคูณสิ่งนี้เข้าไปกับการทำงานของทีมที่ต้องดูแลหลายโมเดลพร้อมกัน ความเร็วของความก้าวหน้าจึงกลายเป็นข้อจำกัดที่แท้จริง วิศวกรลงเอยด้วยการใช้เวลาส่วนใหญ่ไปกับการจัดการกลไกของการทดลอง แทนที่จะได้ใช้ความคิดสร้างสรรค์ว่าควรลองทำอะไรต่อไป
ปัญหาไม่ได้อยู่ที่วิศวกรขาดทักษะหรือความทะเยอทะยาน แต่กระบวนการถูกวางโครงสร้างในลักษณะที่จำกัดจำนวนไอเดียที่สามารถทดสอบได้จริงในแต่ละเดือน เมื่อคุณสามารถรันการทดลองได้เพียงหยิบมือต่อโมเดล คุณย่อมพลาดโอกาสในการปรับปรุงที่มีศักยภาพไปอย่างหลีกเลี่ยงไม่ได้
ธรรมชาติของการทดลอง ML แบบทำมือที่ต้องทำเป็นลำดับ
ประเด็นที่ลึกลงไปคือ การทดลอง ML แบบดั้งเดิมนั้นเกือบจะเป็นลำดับขั้นตอนทั้งหมด (Sequential) ตั้งสมมติฐาน, ทดสอบ, ดูผล, แล้วไปขั้นตอนถัดไป การกระทำแต่ละอย่างขึ้นอยู่กับการเสร็จสิ้นของก่อนหน้า การทำงานแบบขนาน (Parallelism) มีน้อยมาก และการละสายตาจากกระบวนการไปช่วงหนึ่งอาจหมายถึงการเสียโมเมนตัมหรือพลาดบางสิ่งที่สำคัญ
ในสเกลระดับ Meta ปัญหานี้ทวีความรุนแรงขึ้นอย่างรวดเร็ว ทีมที่ดูแลโมเดล Meta Ads Ranking ทำงานกับระบบที่ผ่านการปรับปรุงอย่างหนักมาหลายปี “ชัยชนะที่ได้มาง่ายๆ” (Easy wins) นั้นหมดไปแล้ว การปรับปรุงทุกอย่างต้องอาศัยการให้เหตุผลที่ซับซ้อนขึ้น การออกแบบการทดลองที่ละเอียดขึ้น และการวิเคราะห์ที่เข้มข้นขึ้น
เมื่อโมเดลมีความเป็นผู้ใหญ่แล้ว วิธีการแบบ Manual จะเลิกเป็นแค่ความไม่สะดวกเล็กน้อย แต่จะกลายเป็นเพดานที่จำกัดสิ่งที่ทีมสามารถทำได้ นี่คือกำแพงที่ Meta ชนเข้าอย่างจัง และเป็นเหตุผลหลักว่าทำไมแนวทางที่แตกต่างจึงกลายเป็นสิ่งจำเป็น
ขอแนะนำ REA: Autonomous AI Agent ของ Meta สำหรับการทดลอง ML
ความแตกต่างระหว่าง REA กับผู้ช่วย AI แบบตอบสนอง (Reactive)
เครื่องมือ AI ส่วนใหญ่ในงานวิศวกรรมปัจจุบันเป็นแบบตอบสนอง (Reactive) คุณถาม มันตอบ คุณมอบหมายงาน มันทำให้เสร็จ มนุษย์ยังคงเป็นผู้ขับเคลื่อนกระบวนการ และการโต้ตอบจะถูกจำกัดอยู่ภายในเซสชันนั้นๆ
REA ทำงานต่างออกไป มันเป็น AI Agent ที่รับผิดชอบ Workflow ของ ML แบบ End-to-End ครอบคลุมระยะเวลาหลายวัน เมื่อวิศวกรอนุมัติแผนและงบประมาณการคำนวณ (Compute Budget) ล่วงหน้าแล้ว REA จะขับเคลื่อนกระบวนการต่อจากนั้น ตัดสินใจว่าจะรันการทดลองใดต่อไปโดยดูจากผลลัพธ์ที่รวบรวมได้ ปรับตัวเมื่อเกิดข้อผิดพลาด และดำเนินการต่อโดยไม่ต้องคอยเช็กอินตลอดเวลา
ความแตกต่างนี้มีความสำคัญมากกว่าที่เห็นในตอนแรก ผู้ช่วยแบบ Reactive ทำให้งานแต่ละชิ้นเร็วขึ้น แต่ Autonomous Agent อย่าง REA เปลี่ยนโครงสร้างพื้นฐานของวิธีการทำงาน วิศวกรเปลี่ยนจากการเป็นผู้ควบคุมท่อส่งการทดลอง (Pipeline) มาเป็นผู้รีวิวผลลัพธ์ ความสนใจของพวกเขาเปลี่ยนจากการจัดการกลไกมาเป็นการประเมินผลและตัดสินใจในระดับที่สูงขึ้น
REA ใกล้เคียงกับสิ่งที่นักวิจัยเรียกว่าระบบ AI แบบ “Long-horizon” มันไม่ได้แค่ตอบสนองต่อคำสั่ง แต่มันรักษาสถานะ (State), ติดตามความคืบหน้าสู่เป้าหมาย และตัดสินใจตามลำดับขั้นตอนในช่วงเวลาที่ยาวนานเพื่อให้บรรลุเป้าหมายนั้น
3 ความท้าทายหลักที่ REA ถูกสร้างมาเพื่อแก้
ทีมงานที่ Meta ระบุปัญหาที่ชัดเจนสามประการที่ Agent การทดลอง ML อัตโนมัติจำเป็นต้องจัดการ:
อย่างแรกคือ ความเป็นอิสระในระยะยาว (Long-horizon autonomy) การทดลอง ML ไม่เสร็จในไม่กี่นาที การเทรนอาจใช้เวลาหลายชั่วโมงหรือหลายวัน Agent ที่ต้องให้มนุษย์คอยดูอยู่ตลอดไม่สามารถขยายขนาดการทำงานได้ REA ต้องทำงานได้อย่างน่าเชื่อถือข้ามตารางเวลาหลายวันโดยไม่ต้องมีการควบคุมดูแลต่อเนื่อง
อย่างที่สองคือ การสร้างสมมติฐานคุณภาพสูง การรันการทดลองอัตโนมัติจะมีประโยชน์ก็ต่อเมื่อการทดลองนั้นคุ้มค่าที่จะทำ การสร้างสมมติฐานที่มีแนวโน้มจะปรับปรุงประสิทธิภาพของโมเดลจริงๆ แทนที่จะเป็นการสุ่มการตั้งค่าที่เปลืองทรัพยากร ต้องใช้วิธีการที่ซับซ้อนในการดึงความรู้และการสังเคราะห์งานวิจัย
อย่างที่สามคือ การทำงานที่ยืดหยุ่นภายใต้โครงสร้างพื้นฐานจริง โครงสร้างพื้นฐาน ML ขนาดใหญ่นั้นมีความยุ่งเหยิง งานล้มเหลว ทรัพยากรไม่พร้อมใช้งาน การเทรนขาดเสถียรภาพ หาก Agent ส่งเรื่องทุกปัญหาไปให้วิศวกร ก็จะทำลายจุดประสงค์ของการทำงานอัตโนมัติ REA จำเป็นต้องจัดการกับรูปแบบความล้มเหลวทั่วไปได้ด้วยตัวเอง
ความท้าทายทั้งสามนี้กำหนดการตัดสินใจในการออกแบบทุกขั้นตอนของ REA
วิธีที่ REA จัดการ Workflow ของ ML นานหลายสัปดาห์โดยไม่ต้องให้มนุษย์ป้อนข้อมูลตลอดเวลา
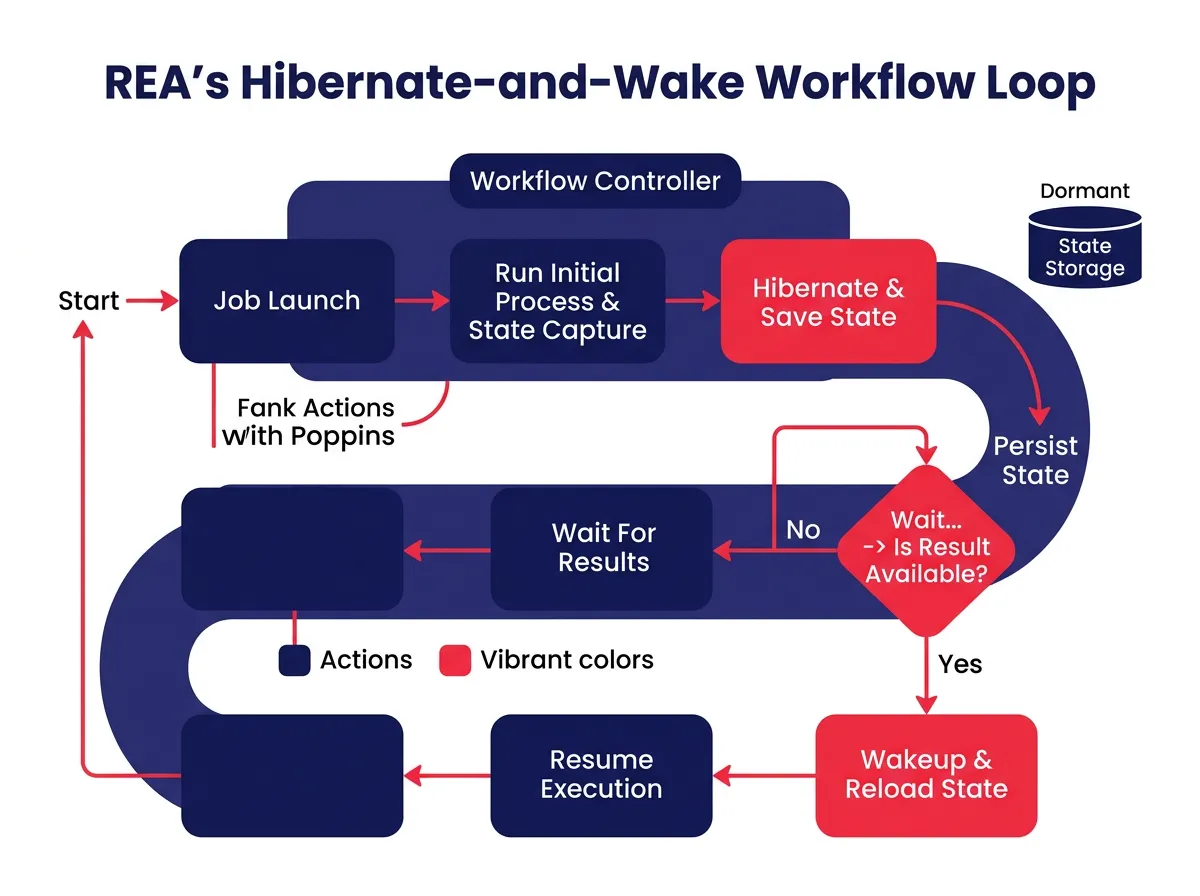
อธิบายกลไก Hibernate-and-Wake (การจำศีลและตื่น)
หนึ่งในปัญหาทางวิศวกรรมที่เป็นรูปธรรมที่สุดที่ REA ต้องแก้ คือสิ่งที่ดูเหมือนชัดเจนที่สุด: AI Agent ทำอะไรในขณะที่รอให้งานเทรนนิ่งเสร็จสิ้น?
ใน Workflow แบบดั้งเดิม วิศวกรจะส่งงานเทรนนิ่งแล้วไปทำงานอื่นในขณะที่ระบบรัน พวกเขาจะกลับมาตรวจสอบเป็นระยะว่าผลลัพธ์พร้อมหรือยัง วิธีนี้ใช้ได้กับมนุษย์แต่ไม่เหมาะกับ Autonomous Agent ที่จำเป็นต้องกลับมาทำงานในสถานะ Workflow ที่เจาะจงเมื่อจงานเสร็จสมบูรณ์
REA แก้ปัญหานี้ด้วยกลไก Hibernate-and-Wake เมื่อ REA เริ่มงานเทรนนิ่งหรือการประเมินผล มันจะบันทึกสถานะปัจจุบันของมัน (Serialize) ว่าอยู่ที่ขั้นตอนใดในแผนการทดลอง สมมติฐานใดถูกทดสอบแล้ว ผลลัพธ์ใดถูกรวบรวมแล้ว จากนั้นจึงเข้าสู่สภาวะ “จำศีล” (Dormant) ซึ่งไม่ใช่การเปิดเครื่องรอแบบกินทรัพยากร แต่เป็นการหยุดพักอย่างมีประสิทธิภาพ
เมื่องานเสร็จสิ้น ระบบ Callback จะปลุก REA ให้ตื่นขึ้น กู้คืนสถานะทั้งหมด และทำงานต่อจากจุดที่ค้างไว้ได้ทันที สิ่งนี้ช่วยให้ REA จัดการ Workflow ที่กินเวลาหลายสัปดาห์และมีการทดลองจำนวนมากได้ โดยไม่ต้องให้ใครมาคอยเฝ้าติดตามหรือส่งต่องานระหว่างขั้นตอน
การออกแบบ Hibernate-and-Wake ยังทำให้ REA ใช้งานได้จริงในสเกลใหญ่ เพราะมันไม่กินทรัพยากรการคำนวณในขณะรอ จึงสามารถรัน REA หลายตัวพร้อมกันในโมเดลที่แตกต่างกันได้โดยไม่เป็นภาระต่อโครงสร้างพื้นฐาน
การสร้างสมมติฐานคุณภาพสูงจากแหล่งข้อมูลเฉพาะทางสองแหล่ง
การรันการทดลองอัตโนมัติจะมีค่าก็ต่อเมื่อสมมติฐานที่ทดสอบนั้นดีพอ นี่คือจุดที่ระบบอัตโนมัติแบบง่ายๆ มักล้มเหลว หากไม่มีกลไกที่แข็งแกร่งในการตัดสินใจว่าจะลองอะไรต่อไป Agent อัตโนมัติจะใช้ไอเดียพื้นฐานจนหมดอย่างรวดเร็ว และเริ่มเผาทรัพยากรไปกับการตั้งค่าที่ไม่มีแนวโน้มจะสำเร็จ
REA จัดการเรื่องนี้ผ่านเครื่องมือสร้างสมมติฐานแบบสองแหล่ง (Dual-source hypothesis engine) ที่ดึงข้อมูลจากสองที่ที่ส่งเสริมกัน
แหล่งแรกคือ ฐานข้อมูลเชิงโครงสร้างของข้อมูลเชิงลึกในอดีต คือการเรียนรู้จากการทดลองที่ผ่านมาของ Meta รวมถึงสิ่งที่ได้ผล สิ่งที่ไม่ได้ผล และภายใต้เงื่อนไขใด เมื่อ REA สร้างสมมติฐานสำหรับโมเดลใหม่ มันจะค้นฐานข้อมูลนี้เพื่อดึงการตั้งค่าและแนวทางที่เคยได้ผลมาแล้ว สิ่งนี้ทำให้ REA เริ่มต้นจากรูปแบบที่ผ่านการพิสูจน์แล้ว แทนที่จะต้องเริ่มจากศูนย์ทุกครั้ง
แหล่งที่สองคือ Deep ML research agent ซึ่งเป็นส่วนหนึ่งของเฟรมเวิร์กที่ Meta เรียกว่า Confucius Agent ตัวนี้จะอ่านและสังเคราะห์งานวิจัยด้าน ML ล่าสุดเพื่อนำเสนอไอเดียที่อาจยังไม่ปรากฏในฐานข้อมูลประวัติ เป็นเทคนิคที่ใหม่พอที่จะยังไม่เคยถูกทดสอบโดย Meta แต่น่าเชื่อถือพอจากหลักฐานงานวิจัยที่จะคุ้มค่าแก่การลอง
ด้วยการผสมผสานความทรงจำขององค์กรจากการทดลองในอดีต เข้ากับไอเดียสดใหม่จากงานวิจัยต่อเนื่อง การสร้างสมมติฐานของ REA จึงมีความสมบูรณ์มากกว่าที่แหล่งข้อมูลใดแหล่งหนึ่งจะสร้างได้เพียงลำพัง แนวทางสองแหล่งนี้คือส่วนสำคัญที่ทำให้ REA สามารถระบุการทดลองที่มีแนวโน้มดีได้ แม้แต่กับโมเดลที่ถูกปรับแต่งมาอย่างหนักแล้วก็ตาม
เฟรมเวิร์กการวางแผน 3 ระยะของ REA และรูปแบบการทำงานที่ยืดหยุ่น
การตรวจสอบ, การรวม และการใช้ประโยชน์: แนวทาง 3 ระยะ
REA ไม่ได้รันการทดลองตามลำดับที่สะดวก แต่มันปฏิบัติตามเฟรมเวิร์กการวางแผน 3 ระยะ (Three-phase planning framework) ที่มีโครงสร้างชัดเจน ซึ่งจะได้รับการยืนยันจากวิศวกรก่อนเริ่มการทดลองใดๆ
ระยะที่ 1 คือ Validation (การตรวจสอบ) REA ทดสอบสมมติฐานแต่ละข้อแยกกัน เพื่อกำหนดว่าไอเดียใดบ้างที่ยังใช้ได้เมื่อทดสอบเดี่ยวๆ ไม่ใช่ทุกสมมติฐานที่ดูดีบนกระดาษจะรอดเมื่อเจอกับข้อมูลเทรนนิ่งจริง ระยะ Validation ถูกออกแบบมาเพื่อคัดกรองไอเดียที่อ่อนแอออกไปก่อนที่จะใช้ทรัพยากรกับพวกมันมากขึ้น
ระยะที่ 2 คือ Combination (การรวม) เมื่อระบุชุดไอเดียที่ผ่านการตรวจสอบแล้ว REA จะเริ่มทดสอบการผสมผสาน การปรับปรุง ML บางอย่างเป็นแบบเสริมกัน (Additive) คือการรวมสองเทคนิคที่ช่วยแยกกันแล้วให้ผลลัพธ์ทวีคูณ บางอย่างอาจทำปฏิกิริยาในแบบที่ไม่คาดคิดซึ่งลดประโยชน์ของแต่ละฝ่ายลง ระยะ Combination ถูกออกแบบมาเพื่อค้นหาการทำงานร่วมกัน (Synergies) และระบุจุดที่ขัดแย้งกันซึ่งอาจมองไม่เห็นจากผลการตรวจสอบเดี่ยวๆ
ระยะที่ 3 คือ Exploitation (การใช้ประโยชน์) ในระยะสุดท้าย REA จะมุ่งเน้นการใช้ทรัพยากรการคำนวณไปกับตัวเลือกที่มีแนวโน้มดีที่สุดที่ระบุได้จากสองระยะแรก เป้าหมายคือการรีดประสิทธิภาพการปรับปรุงออกมาให้ได้มากที่สุดจากการตั้งค่าที่ดีที่สุด ภายใต้งบประมาณการคำนวณที่ได้รับอนุมัติ
โครงสร้างนี้ไม่ได้เป็นเพียงความก้าวหน้าทางตรรกะ แต่ยังเป็นมาตรการป้องกันความเสี่ยง ด้วยการเริ่มจากการทดสอบที่ง่ายกว่าและเลื่อนการลงทุนทรัพยากรหนักๆ ไปไว้ระยะหลัง REA จึงหลีกเลี่ยงการสิ้นเปลืองทรัพยากรไปกับไอเดียที่ควรจะถูกคัดออกตั้งแต่ต้นหากทดสอบแยกกัน





