The Google May 2026 Broad Core Update finished rolling out on June 2, 2026 — and the data is striking. 97.99% of top-100 rankings experienced position changes, position-one CTR on AI Overview queries collapsed from 27% to as low as 11%, and brands cited inside AI Overviews gained +35% organic clicks versus competitors that were not cited. If you manage a website, this is not a routine volatility event you can wait out. It is a structural reset of how Google evaluates content quality, topical authority, and what it means to "rank."
This guide covers what actually happened, which sites won and lost, how to build a clean diagnostic baseline, and the specific actions that drive real recovery — including how to position your content to be cited in AI Overviews rather than buried beneath them.
What the Google May 2026 Broad Core Update Actually Is
A broad core update is not a penalty and it does not target specific sites for violations. Google describes it as "a regular update designed to better surface relevant, satisfying content for searchers from all types of sites." What this means in practice is that Google re-calibrates how it weights quality signals across its entire index simultaneously.
Think of it less as a punishment and more as a periodic re-grading of the entire exam. Every site gets re-scored against updated criteria. Sites whose content has improved since the last update gain. Sites that have not improved — or whose competitors have improved faster — lose ground.
The May 2026 update is the second broad core update of 2026, following the March 2026 update. What makes this cycle particularly significant is that it arrived simultaneously with Google's post-Google I/O rollout of AI Mode, the Gemini 3.5 Flash-powered search interface redesign, and the announcement of Google's "Information Agents" — AI systems that browse the web on a user's behalf to complete tasks. These are not coincidental. They are interconnected.
Key Distinction: A core update drop is not a manual penalty. There is no reconsideration request to file. Recovery comes from genuine content quality improvement — and that takes months, not days.
Timeline and Rollout Facts
Google announced the May 2026 Broad Core Update on May 21, 2026 via the Search Status Dashboard. The rollout completed on the morning of June 2, 2026 — a total duration of approximately 11 days and 21 hours.
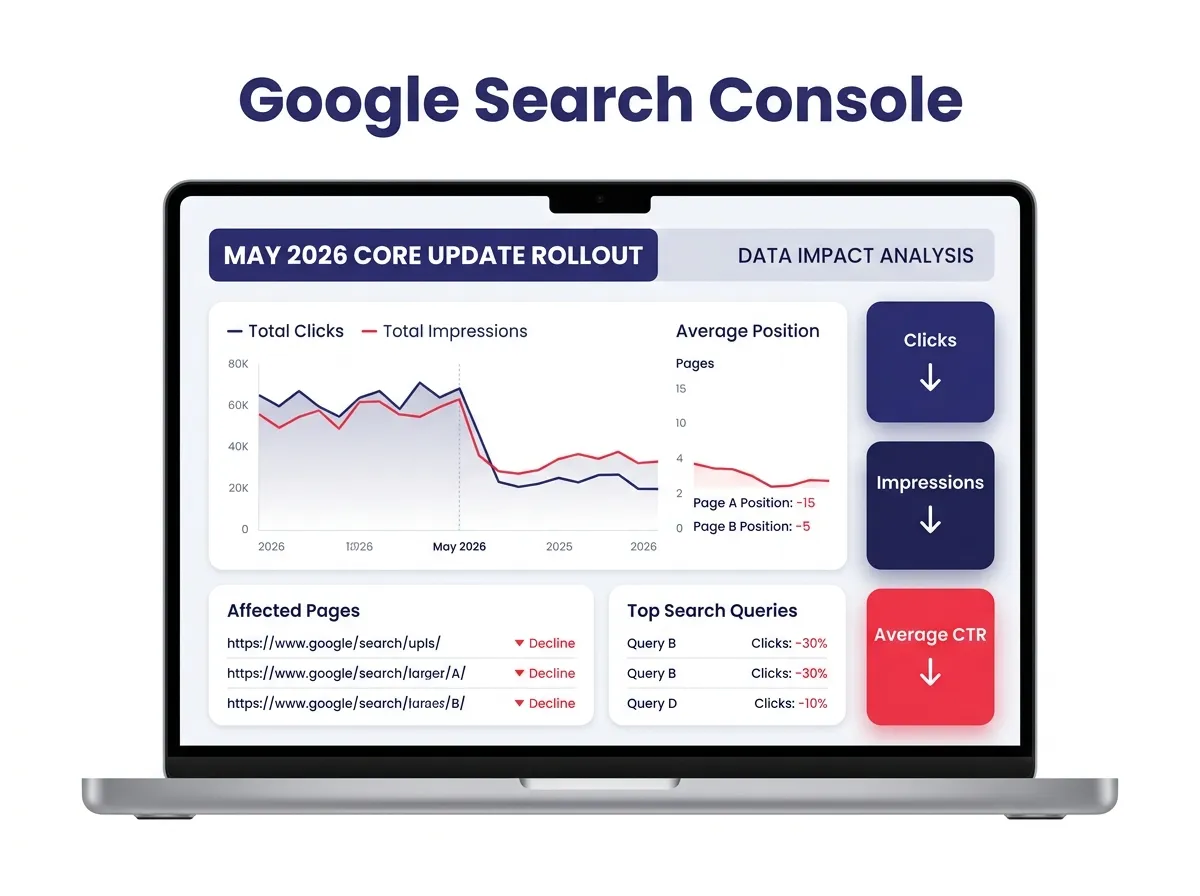
During the rollout window, volatility data from rank-tracking platforms showed unprecedented movement. By the time the update settled:
- 76.03% of TOP 3 rankings experienced position changes
- 88.39% of TOP 10 rankings experienced changes
- 97.99% of TOP 100 rankings experienced changes
- Reddit's share of top-3 positions rose to 10.24% — meaning more than one in ten top-three positions now belongs to Reddit
The standard advice applies: do not make reactive content changes during an active rollout. Your Search Console data is noisy during the rollout period. Changes made now introduce noise you cannot later interpret. The earliest reliable baseline window opened around June 9–10, 2026.
The Double Wave: Core Update Meets AI-Native SERPs
This is probably the most important conceptual shift for understanding what this update is actually doing to your traffic — and why impression loss and click loss are two separate problems that require separate solutions.
A traditional core update shifts how Google weights quality signals across its index. Rankings go up or down based on how your content compares to everything else being re-evaluated. That part is familiar.
What is new in this cycle is the simultaneous rollout of an AI-native SERP that changes what "ranking" actually delivers. Position-one organic CTR on AI Overview-heavy queries has fallen from roughly 27% to as low as 11% — a traffic loss of nearly 60% from the same ranking position, with no change in average position at all. This means you can rank first and still lose more than half your clicks.
This creates two distinct signals in Search Console that must be diagnosed separately:
| Signal | What You See in GSC | Root Cause | Primary Fix |
|---|---|---|---|
| Impression loss | Clicks and impressions both down | Traditional core update ranking drop | Content quality and topical depth |
| CTR loss, stable impressions | Clicks down, impressions flat or up | AI Overview click suppression | Schema optimization and citation strategy |
| Double wave (both) | Clicks way down, impressions slightly down | Core update drop + AI suppression | Schema first, then content depth |
Identifying which pattern you are seeing is the single most important diagnostic step before you do anything else. Applying a content-quality fix to a CTR problem wastes months. Applying a schema fix to a genuine ranking drop ignores the real issue.
Which Sites Won and Lost: Niche-by-Niche Breakdown
The pattern of winners and losers from this update is revealing, because it maps directly onto what the update is actually measuring.
Hardest hit categories:
- Gambling: SEO practitioners reported severe volatility, consistent with gambling's classification as a hyper-YMYL niche where trust signals are scrutinized most heavily.
- Thin e-commerce: Product pages with generic copy that could apply to any competitor were reassigned to competitors with original product descriptions, real customer photos, and specific claims.
- Aggregators and directories: Job portals, travel comparison sites, and price-aggregation sites built on interchangeable page templates saw large losses where more helpful originals exist.
- Affiliate content: Sites relying on generic AI-generated affiliate reviews without genuine hands-on experience. 71% of affiliate marketing sites experienced measurable ranking declines.
- Generic informational publishers: Sites whose primary traffic came from high-volume "What is X" queries now face AI Overviews resolving those queries in-place, eliminating the click.
Categories showing stability or gains:
- Niche authority sites: Deep-expertise sites covering a narrow topic space thoroughly across guides, comparisons, FAQs, and case studies showed some of the strongest gains. This aligns precisely with what the update rewards.
- E-commerce with strong product signals: Transactional pages serving a real purchase decision — with original photography, real reviews, and specific product data — remained relatively stable.
- Local services: Service businesses with strong local signals and actionable content (booking, pricing, location) were less affected because AI Overviews cannot complete the real-world action.
- Reddit (UGC with genuine experience): Reddit's top-3 share rose to 10.24% because it provides the raw, unfiltered first-person experience signals that this update explicitly rewards.
E-E-A-T and Topical Authority: What This Update Actually Rewards
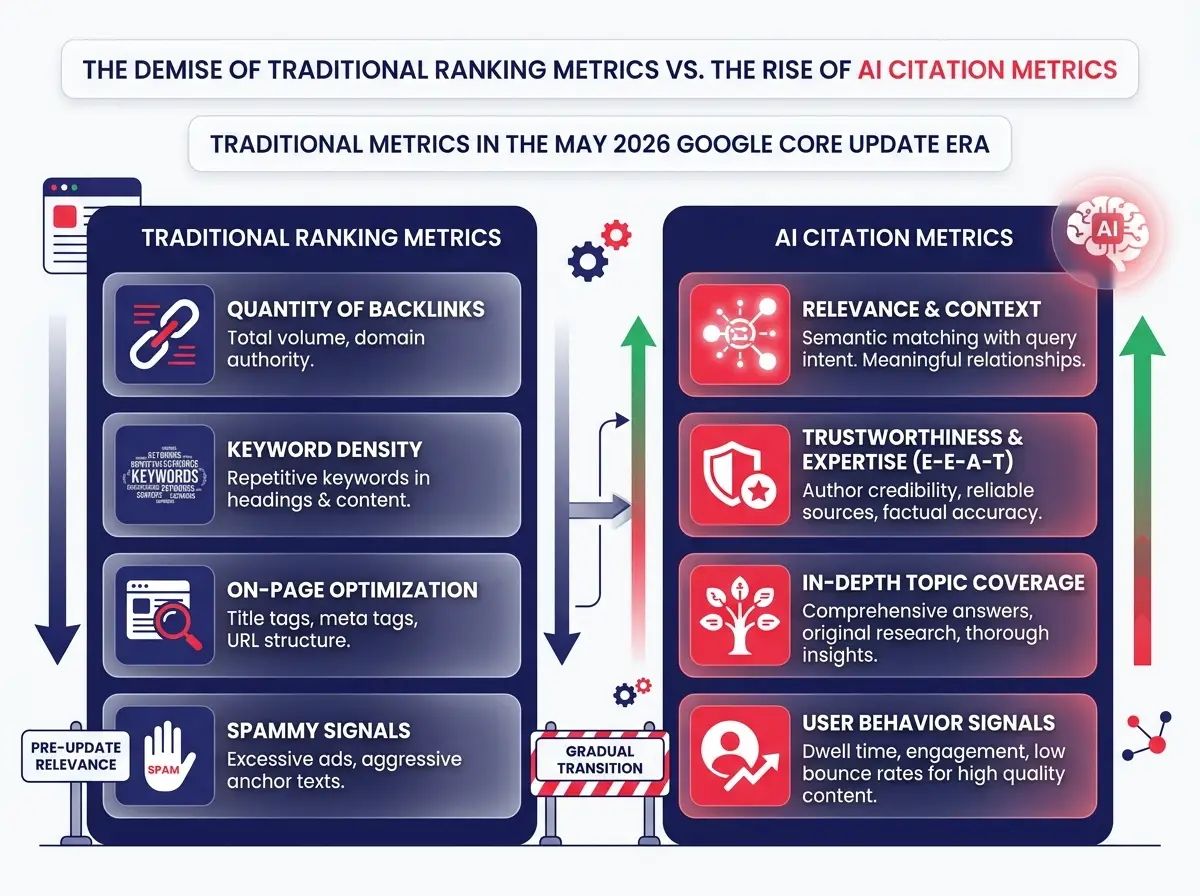
E-E-A-T — Experience, Expertise, Authoritativeness, and Trustworthiness — has expanded scope in this update cycle. Previously, E-E-A-T was most aggressively applied to health and finance (YMYL) content. The May 2026 update extends these requirements to practically all comparative searches, including e-commerce reviews, SaaS comparisons, and how-to guides.
More importantly, how E-E-A-T is evaluated has shifted from the individual page level to the topical cluster level.
What this means in practice:
- Experience signals carry more weight when they appear consistently across multiple related pages — not just in a single author bio. A site where every post about a topic shows real practitioner experience outperforms a site with one exceptional expert article.
- Expertise is evaluated at the topical cluster level. A site that covers a subject across guides, comparisons, definitions, case studies, and how-to articles signals deeper domain expertise than a site with one high-quality standalone page.
- Authoritativeness now includes how many credible sources in the same topic space reference your content ecosystem. Single-page link-building is less effective than establishing your site as a hub that others cite.
- Trust has gained explicit technical dimensions: structured data accuracy, schema completeness, and site architecture clarity are increasingly treated as trust signals, not just technical nice-to-haves.
Pages without clear author attribution dropped an average of 8 positions in this update cycle. Adding named, credentialed authors — with linked bio pages showing their qualifications and publication history — is one of the highest-ROI recovery actions available.
If your site has been running a "best individual pages" strategy, this update is a clear signal to shift toward a "deepest topical authority" approach instead. Your content strategy needs to be built around topic ecosystems, not individual articles.
AI Overviews and the Citation Economy: The New SEO Benchmark
The single most underappreciated insight from this update cycle is buried in one data point: brands cited inside AI Overviews after the May 2026 Core Update gained +35% organic clicks and +91% paid clicks versus competitors that were not cited.
This flips the traditional SEO logic. Being the number-one ranked result beneath an AI Overview is now less valuable than being cited as a source inside that Overview. The click stays above the fold.
What determines whether your content gets cited in AI Overviews? The Gemini models that power these Overviews are evaluating source trustworthiness across several dimensions:
- Topical breadth of the citing domain: The model favors sites that cover the subject comprehensively across multiple formats — it is asking "Does this site know this topic deeply, or does it have one good page?"
- Structured data completeness: Schema-tagged content is easier for the model to parse, extract from, and attribute. Pages with accurate, complete structured data are more likely to be cited.
- Freshness signals: Stale content with outdated statistics or out-of-date claims is less likely to be cited in Overviews that need to provide accurate current information.
- Multimodal citability: AI systems are now pulling from images with proper alt attributes, embedded video transcripts, and structured diagrams. Your citation surface is no longer limited to your written text.
For informational queries, this is the new benchmark: not "did I rank?" but "was I cited?" Sites that are not appearing as cited sources in AI Overviews for their core queries now have a priority problem that keyword rank tracking cannot reveal.
How to Build Your Post-Update Baseline in Search Console
The most common mistake after a core update is skipping straight to content changes. You cannot respond intelligently to something you have not measured cleanly. Build your baseline first.
Step 1: Set your comparison windows
In Search Console, compare the 90-day period ending May 20, 2026 against the period beginning June 9, 2026 onward. This gives you a clean pre-update window versus a post-rollout settling window, avoiding the noisy volatility period in between. Do not use a 28-day comparison — it will include rollout noise in both windows.
Step 2: Segment by three dimensions simultaneously
- Query intent: Separate informational, navigational, and transactional queries. These often moved in opposite directions — collapsing them into a single view hides the real story.
- Page category / topic cluster: Group your URLs by subject area. You are looking for which topic clusters lost and which held — not which individual pages.
- Device type: Mobile and desktop frequently tell different stories during core updates. A mobile-specific ranking drop often points to page experience issues rather than content quality.
Step 3: Identify your loss pattern using the diagnostic table above
Start with your 20 highest-traffic pages. Classify each as impression loss, CTR loss, or both. Do not mix surfaces: Web Search, Discover, and News all report differently in GSC and move for different reasons. Filter to Web search only when doing core update analysis.
Step 4: Prioritize your highest-intent flagship pages
The marginal value of position 1 has risen in 2026 because AI Overviews concentrate click-through power at the very top. Recovering a flagship high-intent page from position 5 to position 2 is worth more than recovering ten minor informational pages. Rank your recovery targets by potential traffic value, not alphabetically.
The Core Update Recovery Checklist
This checklist covers the actions that drive real recovery. Do not start with title tweaks or keyword density adjustments — those are not the problem and they are not the solution.
Content quality and depth:
- Identify the query's true intent and verify your page satisfies it fully. If a user reads your page and still has follow-up questions they need to Google, your page is incomplete.
- Add original insight, data, examples, or case studies that competitors do not have. Generic analysis that mirrors what every other ranking page says is exactly what this update deprioritizes.
- Update all statistics and claims to reflect 2025–2026 data. Stale content with outdated figures loses citation priority.
- Check whether your page covers the topic at the right depth relative to competition. Use a gap analysis: list every question a user might reasonably have about the topic, then verify your page answers all of them.
E-E-A-T and authorship:
- Replace generic "Editorial Team" bylines with named, credentialed authors. Include a linked bio page with verifiable qualifications, external mentions, and publication history.
- Add experience signals — not just credentials. First-person accounts, original testing, real-world examples, and specific practitioner details outperform polished but generic expertise.
- Ensure experience signals appear consistently across your topic cluster, not just on your flagship page.
Structure and scannability:
- Use multi-format content: comparison tables, bulleted lists, numbered steps, callout boxes, and FAQ sections. Structured answers are easier for both readers and AI systems to extract value from.
- Ensure the core answer to the primary query appears within the first 100–150 words. AI Overviews and featured snippets favor pages that front-load their answer.
- Add FAQ schema to your FAQ sections so they are eligible for rich results and AI Overview citation.
Technical trust signals:
- Audit your structured data for errors using Google's Rich Results Test and Schema Markup Validator. Inaccurate or incomplete schema is increasingly treated as a trust-degrading signal.
- Review internal linking within your topic cluster. AI systems and Google's crawlers need to navigate your site efficiently — orphaned pages or broken cluster links reduce your topical authority signal.
- Verify alt text on all images within recovering pages. Descriptive, context-rich alt text makes images citable independently of your written content.
Schema, Structured Data, and Agentic Search
At Google I/O 2026, Google announced "Information Agents" — AI systems that browse the web on a user's behalf to complete tasks and gather information. This is directly relevant to how you should interpret this core update, because the May 2026 Broad Core Update appears to be laying groundwork for how agentic systems evaluate source reliability.
Machine-readable site architecture matters more than at any previous point in SEO. Here is what that means practically:
- Schema accuracy over schema breadth: Adding more schema types without ensuring accuracy in existing schema is counterproductive. One error-free, complete Article or Product schema outperforms five partially-complete schema types with validation warnings.
- FAQ schema on all FAQ content: Every FAQ section is a potential AI Overview citation source. Unmarked FAQs are invisible to the extraction layer.
- HowTo schema for process content: Step-by-step content with proper HowTo markup is significantly more likely to be surfaced in AI Mode responses.
- Site architecture clarity: Agents navigating your site need logical URL structures, consistent category hierarchies, and clean internal linking. Sites that are easy for automated systems to navigate are treated as more reliable sources.
One important note on llms.txt: there has been significant hype around this text file format as a way to communicate directly with AI models. Google has not prioritized it as a trust signal. Chasing llms.txt while ignoring foundational schema work is the wrong order of operations. Fix your structured data first.
Beyond text, citation surfaces now include images with descriptive alt attributes, embedded video transcripts (make these available and structured on-page), and labeled diagrams or charts. Your citation footprint in 2026 extends across all content formats your pages contain.
Realistic Recovery Timelines and What to Expect
Recovery from a broad core update is not fast, and setting accurate expectations prevents panic-driven decisions that create more problems.
The realistic recovery curve looks like this:
| Phase | Timeline | What Happens |
|---|---|---|
| Stabilization | Weeks 1–2 post-rollout (June 2–16) | Rankings settle, data becomes interpretable. No changes yet. |
| Diagnosis | Weeks 2–4 (June 9–30) | Build clean baseline, identify loss patterns, prioritize pages. |
| Content improvement | Months 1–3 (July–September) | Implement changes on highest-priority pages. Schema first, then content depth. |
| Early signal | Months 2–4 | Some incremental improvement visible in GSC as Google re-crawls updated pages. |
| Full recovery assessment | Next core update (likely Q3 2026) | Most significant recoveries happen when the next core update re-evaluates improved content. |
The hardest thing to accept is that cosmetic edits — title rewrites, keyword density adjustments, adding a few sentences — will not move recovery timelines. Real content quality improvements that require genuine effort and original information are what the next core update will re-assess. If you implement real improvements now, you are positioned well for the next update cycle. If you implement surface-level changes, you are positioned for another disappointment.
One important note about the March 2026 Core Update: sites that implemented meaningful content improvements after March saw measurable gains earlier than expected, with some showing incremental recovery between core updates. The lesson: do not wait for the next update to start — start now, because partial recovery between updates is real and documented.
The June 2026 Spam Update: What You Also Need to Know
Separate from the May broad core update, Google rolled out a June 2026 Spam Update. These are different mechanisms targeting different problems, and it is important not to conflate them.
The spam update specifically targets:
- Sites mass-producing AI-generated content without meaningful human editorial oversight or original insight
- Scaled content abuse — creating large volumes of pages whose primary purpose is to rank rather than to help users
- Link spam patterns that violate Google's spam policies
- Cloaking and other deceptive practices that show different content to users versus Googlebot
If your site was hit by the spam update, recovery requires a different process: identify the violating content or practices, remove or noindex it, address the underlying practices, and submit a reconsideration request if a manual action was issued. This is fundamentally different from broad core update recovery, which has no reconsideration process.
Check the Manual Actions report in Search Console. If there is no manual action listed, the spam update did not directly penalize your site — any losses around that period are either residual May core update effects or organic ranking changes, not spam penalties.
Combining your core update recovery strategy with your spam update response into a single plan is a common and costly error. Diagnose each separately, then address them in parallel if both apply.
Frequently Asked Questions
When did the Google May 2026 Core Update start and finish?
The Google May 2026 Broad Core Update began on May 21, 2026 and completed on June 2, 2026 — a total rollout duration of approximately 11 days and 21 hours. It is the second broad core update of 2026, following the March 2026 update.
How is a broad core update different from a spam update or a penalty?
A broad core update recalibrates how Google's ranking systems evaluate quality signals across the entire index. No specific site is targeted for violations. A spam update targets specific practices that violate Google's spam policies. A manual penalty targets a specific site after human review. Broad core update drops have no reconsideration process — recovery requires genuine content improvement.
My impressions are stable but my clicks dropped sharply. Is this a core update problem?
Stable impressions with a sharp click drop is the signature of AI Overview click suppression, not a traditional core update ranking drop. Your page is still ranking in approximately the same position — but an AI Overview is now answering the query above your result, absorbing clicks that previously came to you. The fix is different: focus on structured data optimization and positioning your content as a citable source inside those Overviews, rather than rewriting the page for ranking signals.
Which types of sites were most affected by the May 2026 Core Update?
The hardest-hit categories include gambling sites, thin e-commerce product pages with generic copy, content aggregators and directory sites, affiliate content built on generic AI-generated reviews, and broad informational publishers whose traffic relied on high-volume "What is X" queries now resolved by AI Overviews. Niche authority sites, transactional e-commerce with strong product signals, and local services businesses showed relative stability or gains.
How long does Google Core Update recovery typically take?
Meaningful recovery typically takes 3 to 6 months. The most significant ranking recoveries usually follow the next core update after content improvements have been implemented and re-crawled. Incremental improvements can appear between updates, but the largest gains register when Google's systems formally reassess your content quality in the next update cycle. Do not expect overnight recovery from title changes or minor edits.
Does getting cited in AI Overviews actually drive traffic?
Yes — significantly more than ranking beneath an AI Overview. Brands cited inside AI Overviews after the May 2026 Core Update gained +35% organic clicks and +91% paid clicks versus competitors not cited. The click occurs above the fold, inside the Overview, before users scroll to organic results. Being cited is now more valuable than holding the top organic position beneath an AI-answered query.
Should I change my content while the core update is still rolling out?
No. Making reactive content changes during an active rollout introduces noise that prevents you from reading your actual baseline performance once the update settles. Wait until the rollout window closes and allow at least one full week of clean post-rollout data before acting. Panic editing during a rollout is one of the most common and most consequential mistakes site owners make.
What is the most important first action after a core update ranking drop?
Build a clean diagnostic baseline in Search Console before changing anything. Segment your data by query intent, page category, and device. Classify each affected page as experiencing impression loss, CTR loss, or both — because each pattern requires a different response. Only after you understand which problem you are solving should you move to content and technical improvements. The diagnosis step takes days; skipping it can waste months of effort fixing the wrong thing.