
เว็บไซต์ของคุณผ่านการทดสอบประสิทธิภาพทุกรายการ โหลดภายในเวลาไม่ถึงสองวินาที และแสดงผลได้ดีบนทุกอุปกรณ์ แต่ระบบค้นหา AI อย่าง ChatGPT, Perplexity และ Claude อาจกำลังอ้างอิงเนื้อหาของคู่แข่งแทนที่จะเป็นของคุณ สาเหตุไม่ได้เกี่ยวกับคุณภาพของเนื้อหาหรือโปรไฟล์ backlink แต่เกี่ยวกับ เวลา ที่เนื้อหาของคุณปรากฏจริงในการตอบสนอง HTML
เฟรมเวิร์ก JavaScript สมัยใหม่สร้างช่องว่างในการเรนเดอร์ ผู้ใช้เห็นเนื้อหาที่ AI crawler ไม่เคยได้รับ เพราะเนื้อหานั้นโหลดหลังจากที่ HTML snapshot เริ่มต้นถูกส่งไปแล้ว Seo Audit ส่วนใหญ่พลาดปัญหานี้ไปอย่างสิ้นเชิง และข้อมูลจาก Google Search Console ก็ไม่ได้สะท้อนให้เห็นว่า LLM crawler ดึงข้อมูลจากหน้าเว็บของคุณอย่างไร
นั่นคือเหตุผลที่ JavaScript hydration คือจุดบอดที่ใหญ่ที่สุดของ SEO และ GEO ของคุณในตอนนี้
JavaScript Hydration ทำให้เนื้อหาล่องหนจาก AI Crawler ได้อย่างไร
JavaScript hydration คือ กระบวนการที่เบราว์เซอร์ดาวน์โหลด HTML shell แล้วรัน JavaScript เพื่อเติมเนื้อหาจริงลงไป สำหรับผู้ใช้ ประสบการณ์ดูเหมือนราบรื่น หน้าเว็บดูสมบูรณ์ แต่สิ่งที่เซิร์ฟเวอร์ส่งออกมาในตอนแรกกับสิ่งที่ผู้ใช้เห็นในที่สุดนั้นเป็นคนละเรื่องกัน
ช่องว่างตรงนั้นคือที่อยู่ของปัญหาการมองเห็นจาก AI ของคุณ
LLM Crawler ไม่ใช่ Googlebot
Google และ Bing ลงทุนอย่างหนักในระบบ rendering pipeline Googlebot ใช้บริการที่อิงกับ headless Chrome ซึ่งประมวลผล JavaScript และ index เวอร์ชันที่เรนเดอร์สมบูรณ์แล้วของหน้าเว็บ อาจไม่ทันทีและมีความล่าช้า แต่ Google ก็เห็นเนื้อหาส่วนใหญ่ของคุณในที่สุด
LLM crawler ทำงานต่างออกไป GPTBot, ClaudeBot และ crawler ที่ป้อนข้อมูลให้ index ของ Perplexity ให้ความสำคัญกับ raw HTML snapshot เป็นหลัก ส่วนใหญ่ข้ามการประมวลผล JavaScript ทั้งหมด เพราะถูกสร้างมาเพื่อความเร็วและขนาดมากกว่าการเรนเดอร์แบบเบราว์เซอร์เต็มรูปแบบ
ซึ่งหมายความว่าช่องว่างการค้นหาของ AI กับช่องว่าง SEO แบบดั้งเดิมเป็นปัญหาแยกกันที่มีสาเหตุต่างกัน การได้คะแนนดีใน Google ไม่ได้ยืนยันว่า AI สามารถอ่านเนื้อหาของคุณได้ สองพฤติกรรมการ crawl ที่แตกต่างกัน และการสับสนระหว่างทั้งสองนำไปสู่การพลาดการแก้ไขที่จำเป็น
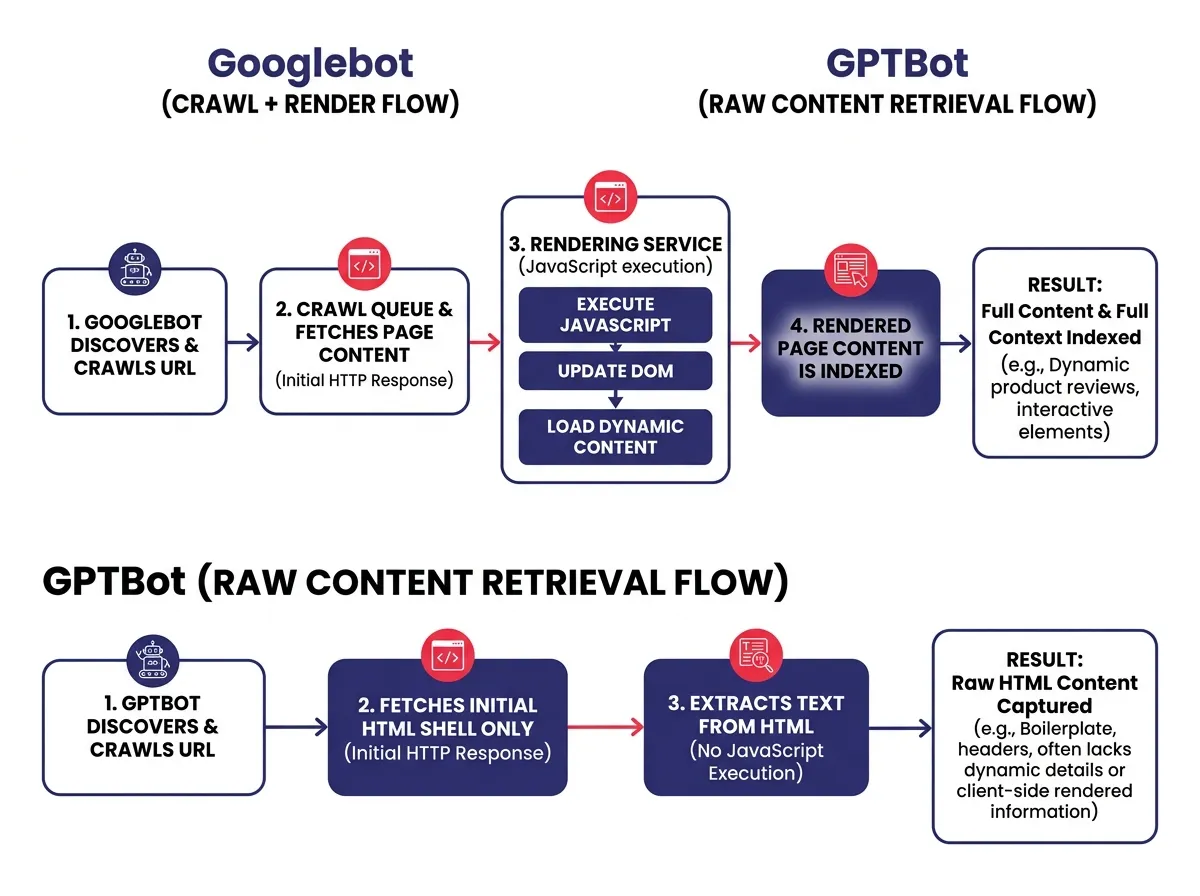
ปัญหา Empty Shell: GPTBot และ ClaudeBot ได้รับอะไรจริงๆ
เมื่อไซต์สร้างด้วย React, Vue, Next.js ในโหมด client-side หรือเฟรมเวิร์กที่คล้ายกัน HTML ดิบมักจะมีลักษณะแบบนี้สำหรับ crawler ที่ไม่ประมวลผล JavaScript:
<div id="root"></div>หรือ wrapper ที่คล้ายกัน- ลิงก์นำทาง
- อาจมีชื่อหน้า
- การอ้างอิง scripts และ stylesheet
- ไม่มีเนื้อหา body จริงๆ เลย
คำอธิบายสินค้า ข้อความบทความ คำอธิบายบริการ FAQ และตารางข้อมูลที่ทำให้หน้าเว็บของคุณมีคุณค่า ล้วนถูกใส่เข้ามาหลังจาก JavaScript รันเสร็จ AI crawler ที่ขอหน้าเว็บโดยไม่ประมวลผล script จะได้รับแค่ empty shell แล้วก็ผ่านไป
นี่ไม่ใช่กรณีขอบที่หายาก แต่พบได้ทั่วไปในแพลตฟอร์ม ecommerce marketing เว็บไซต์ SaaS ไซต์ข่าว และหน้าการตลาดที่สร้างด้วยเฟรมเวิร์กแบบ component-based สมัยใหม่
วิธีวินิจฉัยช่องว่างการดึงข้อมูลของคุณเอง
การทดสอบวินิจฉัยที่เร็วที่สุดไม่ต้องใช้เครื่องมือพิเศษ เปิดเบราว์เซอร์ ปิด JavaScript จากการตั้งค่าของนักพัฒนา แล้วโหลดหน้าสำคัญใดๆ ใหม่อีกครั้ง สิ่งที่คุณเห็นก็คือสิ่งที่ AI crawler ส่วนใหญ่ได้รับโดยประมาณ
หากเนื้อหาของคุณหายไป แสดงว่ามีช่องว่างในการดึงข้อมูล หากหัวข้อ ข้อความเนื้อหา และข้อมูลสินค้าหรือบริการสำคัญยังแสดงอยู่ แสดงว่าคุณอยู่ในสถานะที่ดีกว่า
สำหรับการตรวจสอบที่ละเอียดยิ่งขึ้น ใช้ curl เพื่อขอ raw HTML ของหน้าเว็บและเปรียบเทียบกับเวอร์ชันที่เรนเดอร์สมบูรณ์ในเบราว์เซอร์ เนื้อหาใดที่ปรากฏในเบราว์เซอร์แต่ไม่อยู่ใน output ของ curl นั้นล่องหนสำหรับ AI crawler และจะไม่มีส่วนในการมองเห็นของ GEO ของคุณ
แก้ไขการมองเห็น AI SEO และ GEO ผ่าน Server-Side Rendering และ Structural Signals
การรู้ว่าคุณมีช่องว่างการดึงข้อมูลเป็นก้าวแรก การแก้ไขต้องการการตัดสินใจในระดับโครงสร้างพื้นฐาน ไม่ใช่แค่ระดับเนื้อหา ข่าวดีคือการแก้ไขเหล่านี้ได้รับการพิสูจน์แล้วและไม่จำเป็นต้องสร้าง frontend ทั้งหมดใหม่
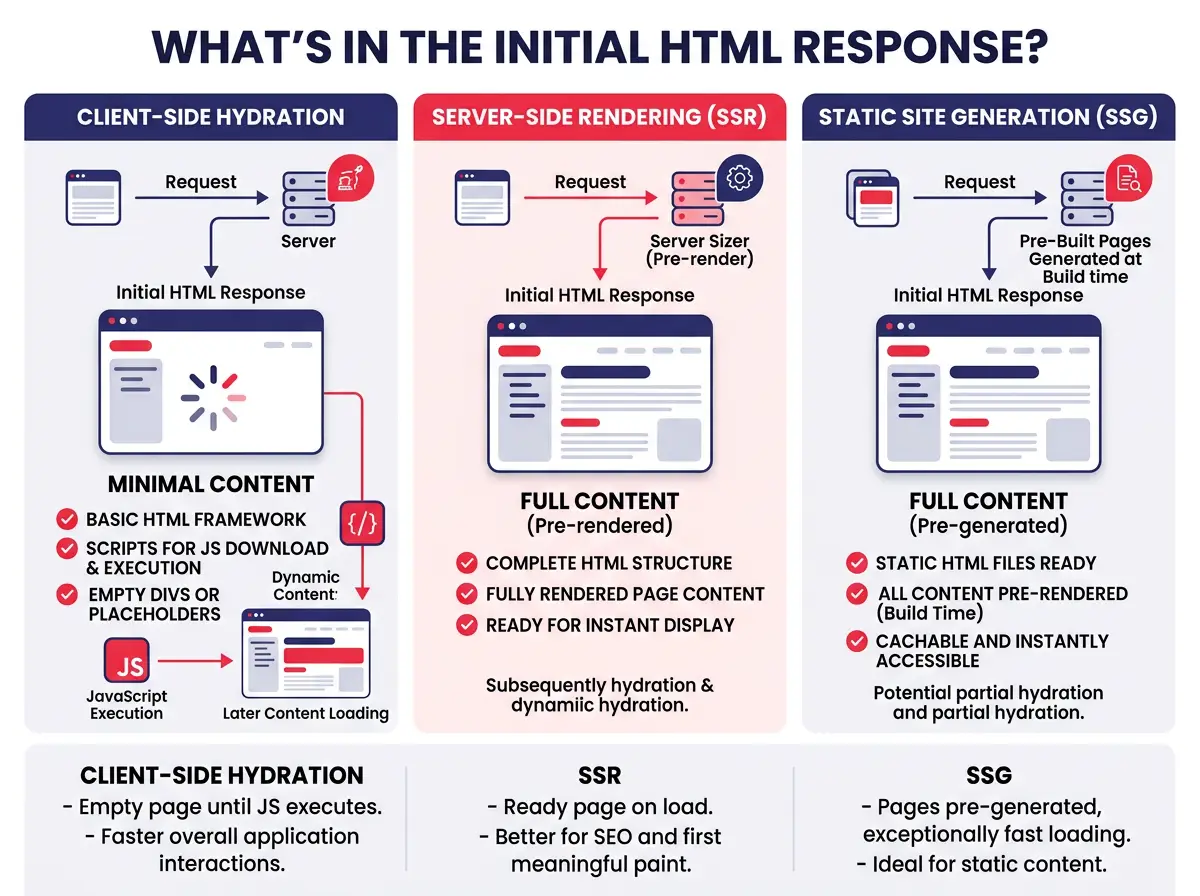
SSR, SSG และเหตุผลที่ Initial Payload คือทุกสิ่ง
SSR และ SSG ทำให้เนื้อหาของคุณมีอยู่ใน raw HTML ก่อนที่ JavaScript จะรัน นี่คือการเปลี่ยนแปลงทางเทคนิคที่มีผลกระทบมากที่สุดที่คุณสามารถทำได้สำหรับ AI SEO และ GEO
- SSR (Server-Side Rendering) สร้าง HTML ฉบับสมบูรณ์บนเซิร์ฟเวอร์ก่อนส่งไปยังเบราว์เซอร์
- SSG (Static Site Generation) สร้างหน้าเว็บไว้ล่วงหน้าในขั้นตอน deploy
- ทุก crawler ได้ประโยชน์ เพราะเนื้อหา body ที่สำคัญมีอยู่ใน initial payload โดยไม่คำนึงถึงความสามารถในการประมวลผล JavaScript
- เฟรมเวิร์กหลัก อย่าง Next.js, Nuxt, Astro และ SvelteKit รองรับทั้งสองแนวทางโดยตรง
- แนวทางผสม (static shells + client-side data fetching) ทำงานได้ดีสำหรับประสิทธิภาพ แต่เนื้อหาใดที่สำคัญสำหรับการค้นหาและการอ้างอิงของ AI ต้องอยู่ใน server-rendered payload
Structural Signals ที่ช่วยให้ AI เชื่อถือและอ้างอิงเนื้อหาของคุณ
การแก้ไข rendering ทำให้เนื้อหาของคุณเข้าสู่ HTML การ ใส่ structural signals กำหนดว่า AI จะเชื่อถือและอ้างอิงเนื้อหานั้นหรือไม่
JSON-LD schema markup คือหนึ่งในสัญญาณที่เชื่อถือได้มากที่สุดที่คุณสามารถเพิ่มได้ มันให้ข้อความที่สะอาดและมีโครงสร้างที่ LLM สามารถแยกวิเคราะห์ได้โดยไม่ต้องตีความเลย์เอาต์ภาพของคุณ สำหรับบทความ สินค้า FAQ และธุรกิจท้องถิ่น JSON-LD ให้ metadata ที่ชัดเจนแก่ AI เกี่ยวกับสิ่งที่เนื้อหาของคุณครอบคลุมและใครเป็นผู้ผลิต
นอกจาก schema ให้ใส่ใจกับอัตราส่วนข้อความต่อโค้ด หน้าที่เต็มไปด้วยบล็อกนำทางซ้ำๆ ลิงก์ footer สคริปต์การยินยอม cookie และโค้ดติดตาม จะผลักเนื้อหาจริงของคุณลงไปต่ำกว่าใน HTML ระบบ AI ที่วิเคราะห์หน้าเว็บของคุณให้น้ำหนักมากกับเนื้อหาที่ปรากฏโดดเด่นในโครงสร้างเอกสาร ดังนั้นการตัด boilerplate ออกช่วยให้สิ่งที่สำคัญจริงๆ ปรากฏชัดขึ้น
การปรับปรุงโครงสร้างที่ควรให้ความสำคัญ:
- วางเนื้อหาหลักไว้สูงใน DOM ก่อนองค์ประกอบนำทางหรือ sidebar เมื่อเป็นไปได้
- ใช้ semantic HTML elements อย่าง
<article>,<main>และ<section>เพื่อส่งสัญญาณลำดับชั้นเนื้อหา - เพิ่ม JSON-LD markup สำหรับประเภทเนื้อหาหลักในทุกหน้าสำคัญ
- ตรวจสอบอัตราส่วนข้อความต่อโค้ดโดยใช้เครื่องมือที่วัด raw content เทียบกับ markup overhead
- หลีกเลี่ยงการซ่อนเนื้อหาสำคัญไว้หลัง tabs หรือ accordions ที่โหลดเฉพาะเมื่อผู้ใช้โต้ตอบเท่านั้น
การสร้าง Governance Workflow
การแก้ไขทางเทคนิคมักถดถอยเมื่อทีมเปิดตัวฟีเจอร์ใหม่ การตัดสินใจ rendering ที่ถูกต้องในวันนี้อาจถูกย้อนกลับอย่างเงียบๆ สามสปรินต์ต่อมาเมื่อนักพัฒนาเลือกใช้ client-side data fetching บนบล็อกเนื้อหาใหม่
Governance workflow ป้องกันสิ่งนี้ แนวทางไม่ซับซ้อน: กำหนดมาตรฐาน rendering ในระดับ template ที่จำแนกประเภทเนื้อหาใดที่ต้องอยู่ใน server-rendered payload เสมอ เขียนเป็นกฎที่บันทึกไว้อย่างชัดเจน ไม่ใช่การบอกต่อแบบไม่เป็นทางการใน Slack
กฎอาจระบุว่าคำอธิบายสินค้า ข้อมูลราคา และข้อความเนื้อหาบทความเป็นสิ่งสำคัญสำหรับการดึงข้อมูลและต้องไม่ถูกใส่เข้ามาทาง client-side งานฟีเจอร์ใหม่ที่แตะต้องประเภทเนื้อหาเหล่านั้นต้องผ่านการตรวจสอบ rendering ก่อน merge
นั่นคือมาตรฐานที่ชัดเจน และมันปกป้องการมองเห็น AI SEO และ GEO ของคุณเมื่อสถาปัตยกรรม frontend เปลี่ยนแปลง สมาชิกทีมสับเปลี่ยน และเฟรมเวิร์กใหม่ถูกนำมาใช้
องค์กรที่ทำได้ดีในการค้นหาที่ขับเคลื่อนด้วย AI ตอนนี้มักจะปฏิบัติต่อการดึงเนื้อหาเป็นข้อกำหนดทางเทคนิคชั้นหนึ่ง เช่นเดียวกับที่พวกเขาปฏิบัติต่อความเร็วหน้าเว็บหรือ accessibility การมองเห็นโดยระบบ AI ไม่ได้เกิดขึ้นเองโดยอัตโนมัติ แต่ต้องการวิศวกรรมที่ตั้งใจเช่นเดียวกับที่เป้าหมายประสิทธิภาพอื่นๆ ต้องการ






