ความล้มเหลวในการดึงข้อมูล: ทำไมหน้าที่ติดอันดับสูงถึงถูก AI Search มองข้าม
กว่า 60% ของการค้นหาที่ขับเคลื่อนด้วย AI จบลงโดยที่ผู้ใช้ไม่คลิกเลยแม้แต่ครั้งเดียว แต่แบรนด์ที่เข้าใจความแตกต่างระหว่างการถูก “ดึงข้อมูล” กับการถูก “อ้างอิง” กลับครองสรุปผลที่สร้างโดย AI ซึ่งส่งผลต่อการตัดสินใจซื้อของผู้บริโภค ความแตกต่างนี้ฟังดูเรียบง่าย แต่มันเปลี่ยนทุกอย่างในแนวทางการเขียน การจัดโครงสร้าง และการเผยแพร่เนื้อหา
ปัญหาที่ทีม SEO ส่วนใหญ่เจอคือการมองว่า การดึงข้อมูล และ การอ้างอิง เป็นสิ่งเดียวกัน ซึ่งมันไม่ใช่ หน้าเว็บอาจถูก Crawl ประมวลผล และนำไปใช้ประกอบการตอบสนองของ AI โดยไม่ได้รับการอ้างอิงแม้แต่ครั้งเดียว ขณะที่หน้าจากเว็บไซต์เล็กๆ ที่สร้างมาเพื่อการดึงข้อมูลโดยเฉพาะ อาจถูกกล่าวถึงซ้ำๆ ใน AI Overviews และคำตอบของ Perplexity
บทความนี้จะแยกแยะอุปสรรคในแต่ละขั้นตอนระหว่างการถูกพบโดย AI Crawler และการได้รับการยอมรับเป็นแหล่งที่เชื่อถือได้
ความสำเร็จของ SEO แบบดั้งเดิมไม่ได้รับประกัน AI Visibility หน้าที่ติดอันดับ Top 3 ใน Google อาจถูกข้ามไปในขั้นตอนการดึงข้อมูลของ AI การเข้าใจสาเหตุต้องมองที่วิธีที่ Large Language Models ประมวลผลคำถามจริงๆ ก่อนจะตอบสนอง
Fan-out Queries
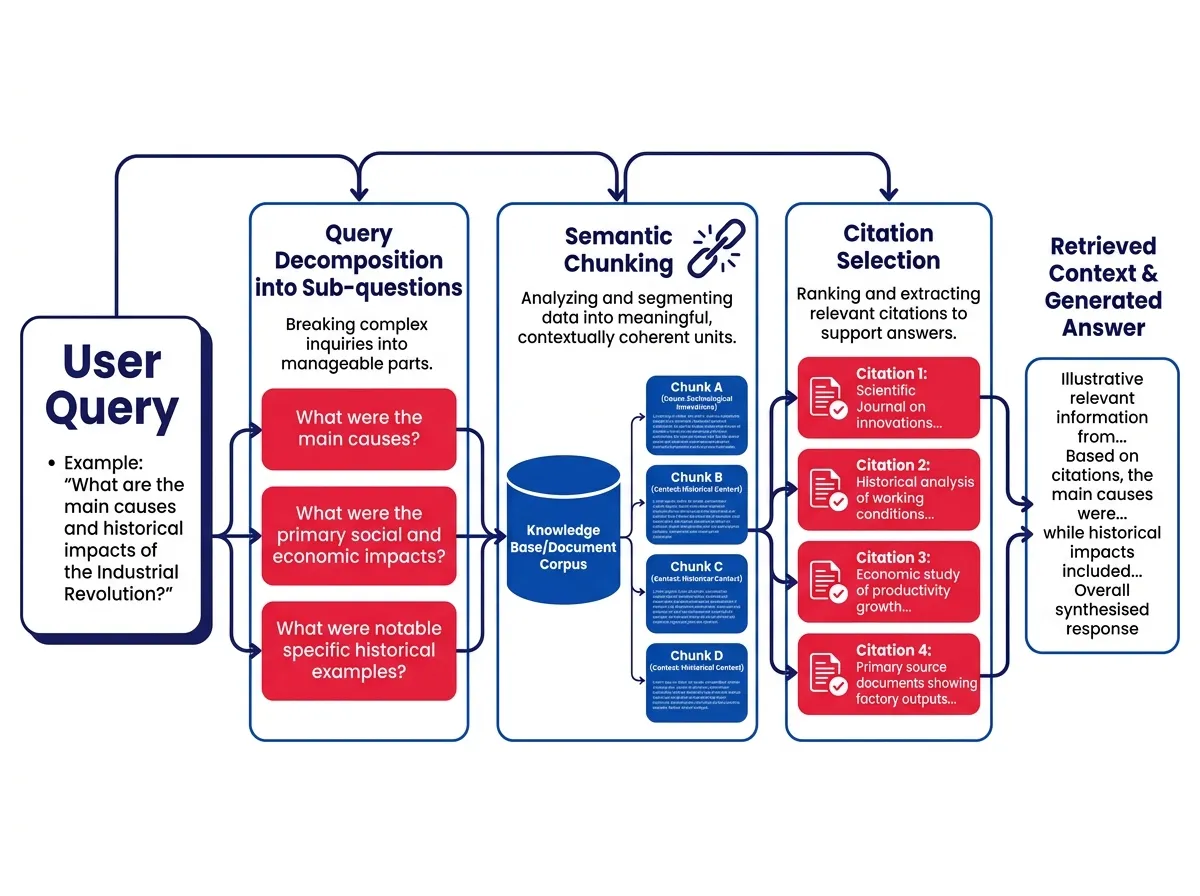
เมื่อผู้ใช้พิมพ์คำถามลงใน AI Search Tool โมเดลจะไม่ประมวลผลเป็นคำค้นหาเดียว แต่จะแบ่งคำถามออกเป็นคำถามย่อยหลายๆ ข้อ ซึ่งเรียกว่า Fan-out Query Generation โดยแต่ละคำถามย่อยจะมีการดึงข้อมูลเป็นรอบๆ ของตัวเอง
นี่คือเหตุผลที่ชื่อหน้าและ URL Slug สำคัญมากกว่าที่ทีม SEO หลายทีมคิด ลองนึกภาพว่าหน้าของคุณมีคีย์เวิร์ด “best CRM software for small businesses” แต่คำถามย่อยภายในของ AI รวมถึง “what CRM integrates with Gmail for small teams” หรือ “CRM pricing tiers under $50 per month” หน้าที่มีชื่อกว้างๆ ของคุณอาจไม่ผ่านการดึงข้อมูลเลยแม้แต่รอบเดียว
สำหรับทีม SEO หมายความว่าต้องตรวจสอบเนื้อหาเทียบกับคำถามย่อยที่กลุ่มเป้าหมายมีแนวโน้มจะค้นหา ไม่ใช่แค่คีย์เวิร์ดหลัก เครื่องมือที่แสดง “People Also Ask” และการค้นหาที่เกี่ยวข้องสามารถใช้เป็นแนวทางคร่าวๆ สำหรับโครงสร้าง Fan-out Query ได้
Semantic Atomicity
ระบบ Retrieval-Augmented Generation (RAG) ทำงานโดยการแบ่งเอกสารออกเป็น Chunk ให้คะแนนแต่ละ Chunk ตามความเกี่ยวข้อง และส่ง Chunk ที่ดีที่สุดเข้าสู่ Context Window ของโมเดล การเขียนแบบบรรยายที่ฝังประเด็นหลักไว้กระจายตลอดหลายย่อหน้าจะถูกลดคะแนน เพราะไม่มี Chunk ไหนที่มีคุณค่าเพียงพอเมื่ออ่านแบบแยกส่วน
Semantic Atomicity คือการเขียนย่อหน้าที่แต่ละย่อหน้ามีความคิดครบถ้วนสมบูรณ์ในตัวเอง แต่ละย่อหน้าควรสื่อความหมายได้แม้อ่านแยกจากส่วนอื่น
ไม่ได้หมายความว่าต้องทำให้เนื้อหาง่ายเกินไป แต่เป็นการจัดแพ็คเกจข้อเท็จจริงในแบบที่รอดพ้นจากกระบวนการแบ่ง Chunk ย่อหน้าที่ขึ้นต้นด้วยข้อเรียกร้องที่ชัดเจน สนับสนุนด้วยข้อมูลเฉพาะเจาะจง และปิดด้วยผลสรุปเชิงปฏิบัติ มีโอกาสถูกดึงข้อมูลสูงกว่ามาก
Citation Hierarchy
มีความแตกต่างที่แท้จริงระหว่างเนื้อหาที่ให้ข้อมูลแก่ AI Model และเนื้อหาที่ได้รับการอ้างอิงโดยตรง เนื้อหาจาก Reddit, YouTube Transcript และ Community Forum มักมีส่วนช่วยสิ่งที่โมเดล “รู้” แต่แทบไม่ได้รับลิงก์อ้างอิงที่มองเห็นได้ในผลลัพธ์สุดท้าย เนื้อหาประเภทนี้อยู่ที่ก้นสุดของลำดับชั้นการอ้างอิง
ส่วนที่อยู่ด้านบนสุดคือเนื้อหาที่มีความหนาแน่นของข้อเท็จจริงสูง มีการอ้างอิงแหล่งที่มาชัดเจนในตัวเนื้อหา มีสัญญาณความเป็นผู้เขียนที่ชัดเจน และมี Schema Markup ที่ช่วยให้เครื่องจักรแยกแยะโครงสร้าง นั่นคือสิ่งที่ทำให้ได้รับการอ้างอิงแบบมีชื่อแบรนด์ ไม่ใช่แค่มีส่วนช่วยความรู้พื้นหลัง
การสร้างเนื้อหาที่พร้อมถูกอ้างอิง: จาก Schema Signals ถึงกลยุทธ์เฉพาะแพลตฟอร์ม
เมื่อเข้าใจว่าทำไมการดึงข้อมูลถึงล้มเหลว ขั้นตอนต่อไปคือการสร้างเนื้อหาที่ผ่านเกณฑ์การอ้างอิง ซึ่งต้องตัดสินใจทั้งในแง่เทคนิคและบรรณาธิการ และแนวทางที่ถูกต้องจะแตกต่างกันตามแพลตฟอร์ม AI ที่คุณกำหนดเป้าหมาย

Schema ในฐานะคู่มือการดึงข้อมูล: ก้าวข้าม Markup ทั่วไปสู่ FAQPage และ HowTo
Schema Markup แบบทั่วไปบอกเครื่องจักรว่าหน้านี้มีอยู่และอยู่ในหมวดหมู่อะไร แต่ Schema Type เฉพาะอย่าง FAQPage, HowTo และ Article ทำได้มากกว่า โดยทำหน้าที่เป็นคู่มือการดึงข้อมูลที่ทำให้โครงสร้างเนื้อหาอ่านได้ง่ายขึ้นสำหรับ AI Parser
FAQPage Schema จับคู่คำถามกับคำตอบโดยตรง เมื่อ AI System พบ Markup นี้ ไม่จำเป็นต้องเดาว่าส่วนไหนของหน้าตอบคำถามเฉพาะเจาะจง คำตอบถูกจัดเตรียมพร้อมดึงข้อมูลแล้ว HowTo Schema ทำสิ่งเดียวกันสำหรับกระบวนการทีละขั้นตอน
ผลลัพธ์เชิงปฏิบัติชัดเจน: สำหรับเนื้อหาที่ตอบคำถามทั่วไปหรือนำผู้ใช้ผ่านกระบวนการ FAQPage และ HowTo Schema ควรถือเป็นมาตรฐาน ไม่ใช่ตัวเลือก
ความแตกต่างของแพลตฟอร์มที่สำคัญจริงๆ: Perplexity vs. ChatGPT vs. Google AI Overviews
แนวทางเนื้อหาเดียวจะให้ผลลัพธ์ต่ำกว่ามาตรฐานบนแพลตฟอร์ม AI หลักทั้ง 3 แห่ง เพราะแต่ละแพลตฟอร์มมีตรรกะการอ้างอิงที่แตกต่างกัน
| แพลตฟอร์ม | สัญญาณการอ้างอิงหลัก | รูปแบบเนื้อหาที่ได้ผล |
|---|---|---|
| Perplexity | ความทันสมัย + การยืนยันจากชุมชน | หน้าที่อัปเดตบ่อยและมีสัญญาณชุมชน |
| ChatGPT | ความลึกแบบสารานุกรม + การระบุแหล่งที่มา | เนื้อหา Long-form ที่มีการอ้างอิงครอบคลุม |
| Google AI Overviews | สัญญาณ Index แบบดั้งเดิม | หน้าที่มี E-E-A-T แข็งแกร่ง, Header มีโครงสร้าง และ Schema |
Perplexity มักให้ความสำคัญกับแหล่งที่อัปเดตล่าสุดและมีสัญญาณความเชื่อถือจากชุมชน ChatGPT ให้รางวัลกับเนื้อหาที่ครอบคลุมพร้อมการระบุแหล่งที่มาชัดเจน ส่วน Google AI Overviews พึ่งพาสัญญาณความเชื่อถือและสิทธิอำนาจเดิมๆ ที่ SEO ของ Google ให้ความสำคัญเสมอมา
Entity Consistency และ Citation Drift
แม้หลังจากได้รับการอ้างอิงแล้ว การรักษาไว้ต้องอาศัยความใส่ใจต่อเนื่อง Citation Drift เกิดขึ้นเมื่อ AI System อัปเดตฐานความรู้หรือปรับลำดับความสำคัญในการดึงข้อมูล ทำให้หน้าที่เคยถูกอ้างอิงหลุดออกจากคำตอบที่สร้างขึ้น
สาเหตุที่พบบ่อยที่สุดของ Drift คือความไม่สอดคล้องของ Entity หากชื่อแบรนด์ ชื่อผลิตภัณฑ์ และข้อเรียกร้องหลักของคุณถูกอธิบายต่างกันบนเว็บไซต์ของคุณเอง บน Schema และในการกล่าวถึงจากบุคคลที่สาม AI System จะสร้าง Entity Model ที่สอดคล้องกันได้ยาก ความไม่สอดคล้องนี้จะทำให้สัญญาณความเชื่อถือลดลงเมื่อเวลาผ่านไป
การรักษาความสอดคล้องของ Entity ทุกช่องทางที่เป็นของคุณ และการจัดการว่าสิ่งพิมพ์ภายนอกอธิบายแบรนด์ของคุณอย่างไร คือการป้องกันเชิงโครงสร้างต่อ Citation Drift
การวัดสิ่งที่สำคัญจริงๆ: AI Visibility Metrics และความเป็นจริงของ No-click
เมื่อการตอบสนอง AI แบบ Zero-click ครองส่วนแบ่งการค้นหาจำนวนมาก กรอบเดิมของการวัดความสำเร็จผ่าน Direct Referral Traffic ไม่สามารถบอกเรื่องราวทั้งหมดได้อีกต่อไป แบรนด์ต้องการ KPI ที่ต่างออกไป
ทำไม AI-referred Traffic ถึงเป็น Vanity Metric
การนับ Click-through จากการตอบสนองที่สร้างโดย AI ฟังดูเหมือนตัวชี้วัดที่เป็นธรรมชาติ แต่มันทำให้เข้าใจผิดได้ เมื่อผู้ใช้ได้รับคำตอบครบถ้วนจากสรุปของ Perplexity หรือ Google AI Overview พวกเขามักไม่คลิกผ่านไปยังแหล่งใดเลย ไม่ได้หมายความว่าเนื้อหาของคุณล้มเหลว อาจหมายความว่ามันประสบความสำเร็จมากจนโมเดลอ้างอิงโดยตรง
ตัวชี้วัดที่บอกได้มากกว่าคือ Branded Search Lift ซึ่งก็คือการเพิ่มขึ้นของการค้นหาชื่อแบรนด์โดยตรงหลังจากได้รับการเปิดเผยผ่าน AI เมื่อใครเห็นแบรนด์ของคุณถูกอ้างอิงในสรุปที่สร้างขึ้น พวกเขามักไม่คลิกทันที แต่จะค้นหาชื่อแบรนด์ของคุณในภายหลังโดยตรงใน Google หรือพิมพ์ URL ของคุณ พฤติกรรมนี้แสดงเป็นการเพิ่มขึ้นของ Branded Search Volume และเป็นสัญญาณที่แม่นยำกว่ามากว่า AI Visibility กำลังขับเคลื่อนผลลัพธ์ทางธุรกิจจริงหรือไม่
ตัวชี้วัดรองที่ควรติดตามรวมถึง Share of Voice ในสรุปที่สร้างโดย AI สำหรับกลุ่ม Topic หลักของคุณ และแนวโน้ม Direct Traffic ที่แบ่งตามช่วงเวลาที่ทราบว่ามีการเปิดเผยต่อ AI
การครองใจในสรุปที่สร้างขึ้น
เป้าหมายเชิงปฏิบัติในสภาพแวดล้อม Zero-click ไม่ใช่การได้รับคลิก แต่คือการครอง Mental Model เมื่อ AI System นำเสนอแบรนด์ของคุณซ้ำๆ เป็นแหล่งข้อมูลหลักสำหรับหัวข้อเฉพาะ คุณกำลังสร้างการรับรู้ที่แปลงเป็นผลลัพธ์ในภายหลัง ผ่าน Branded Search, Direct Visit และ Word-of-mouth
นี่เป็นการเปลี่ยนกลยุทธ์เนื้อหาให้เป็น Brand Infrastructure มากกว่า Traffic Funnel หน้าที่ได้รับการอ้างอิงในการตอบสนอง AI ห้าพันครั้งโดยไม่สร้าง Direct Click เลยแม้แต่ครั้งเดียว อาจยังคงรับผิดชอบต่อ Pipeline ที่สำคัญหากการเปิดเผยเหล่านั้นกำลังขับเคลื่อน Branded Search Lift และ Direct Traffic ในสัปดาห์ต่อมา
การขยายกลยุทธ์เนื้อหาไปยังแพลตฟอร์มบุคคลที่สามที่ LLM ใช้สร้างความน่าเชื่อถือ
รูปแบบที่ชัดเจนที่สุดในการที่ LLM สร้างความรู้เกี่ยวกับ Entity คือเนื้อหานอกเว็บไซต์มีน้ำหนักที่ไม่สมส่วน การวางเนื้อหาในบุคคลที่สามบนสิ่งพิมพ์ที่น่าเชื่อถือ, Expert Roundup และ Listicle ที่ดูแลอย่างดีไม่ใช่กลยุทธ์เสริม แต่เป็น Core Infrastructure สำหรับวิธีที่ AI System สร้างความเชื่อถือต่อแบรนด์
เมื่อแบรนด์ของคุณถูกอธิบายในลักษณะเดิมอย่างสอดคล้องกันจากแหล่งที่โมเดลเชื่อถืออยู่แล้ว รวมถึงสิ่งพิมพ์ในอุตสาหกรรม แพลตฟอร์มรีวิว และเว็บไซต์ Expert Q&A AI จะพัฒนา Entity Model ที่แน่วแน่กว่าสำหรับแบรนด์ของคุณ ความมั่นใจนั้นแปลงเป็นการอ้างอิงที่บ่อยครั้งและโดดเด่นกว่า
กลยุทธ์เชิงปฏิบัติคือการหา Earned และ Paid Placement ในสิ่งพิมพ์ที่ปรากฏใน AI-generated Response สำหรับหัวข้อเป้าหมายของคุณอยู่แล้ว Advertorial, Affiliate-listed Placement และการกล่าวถึงที่ขับเคลื่อนด้วย PR ล้วนมีส่วนช่วย หากเนื้อหาโดยรอบมีคุณภาพสูงและคำอธิบายแบรนด์สอดคล้องกับที่คุณอธิบายตัวเองบน Domain ของคุณเอง
การส่งสารที่สอดคล้องกันข้ามช่องทางที่คุณเป็นเจ้าของและบุคคลที่สามไม่ใช่แค่แนวปฏิบัติด้านการสื่อสาร ในบริบทของ AI Search และ SEO มันคือกลยุทธ์การดึงข้อมูลและการอ้างอิง เครื่องจักรเรียนรู้ว่าคุณคือใครผ่านการซ้ำซากจากแหล่งที่น่าเชื่อถือ และแบรนด์ที่ควบคุมเรื่องราวนั้นทั่วทั้งเว็บคือแบรนด์ที่ปรากฏเมื่อ AI เขียนสรุป